I’ve been in the process of updating my AI Strategy app, and one of the biggest challenges is drilling through these different model leaderboards and identifying the features that surface insights project managers, engineers, and data scientists can…
CBSE delays Class 12 answer book verification and re-evaluation portal launch to June 1, 2026, with extended deadlines and clear post-result guidelines
Evaluating an AI model and evaluating an AI agent are related—but they answer fundamentally different questions. A model benchmark tests the capability of a…
Braintrust joins the Vercel Marketplace with native support for the Vercel AI SDK and AI Gateway, enabling developers to monitor, evaluate, and improve AI application performance in real time.
Students seeking scanned answer books can apply between May 19 and May 22 at a fee of Rs 700 per subject; applications for verification and re-evaluation will be accepted between May 26 and May 29
CBSE explains its Class 12 On-Screen Marking system, stressing transparency, stepwise marking and review options to ensure fair and consistent evaluation.
ARC-Neuron LLMBuilder is a local-first framework for dataset-connected model building, benchmark receipts, candidate/incumbent promotion, archive-ready lineage, and governed small-model improvement.
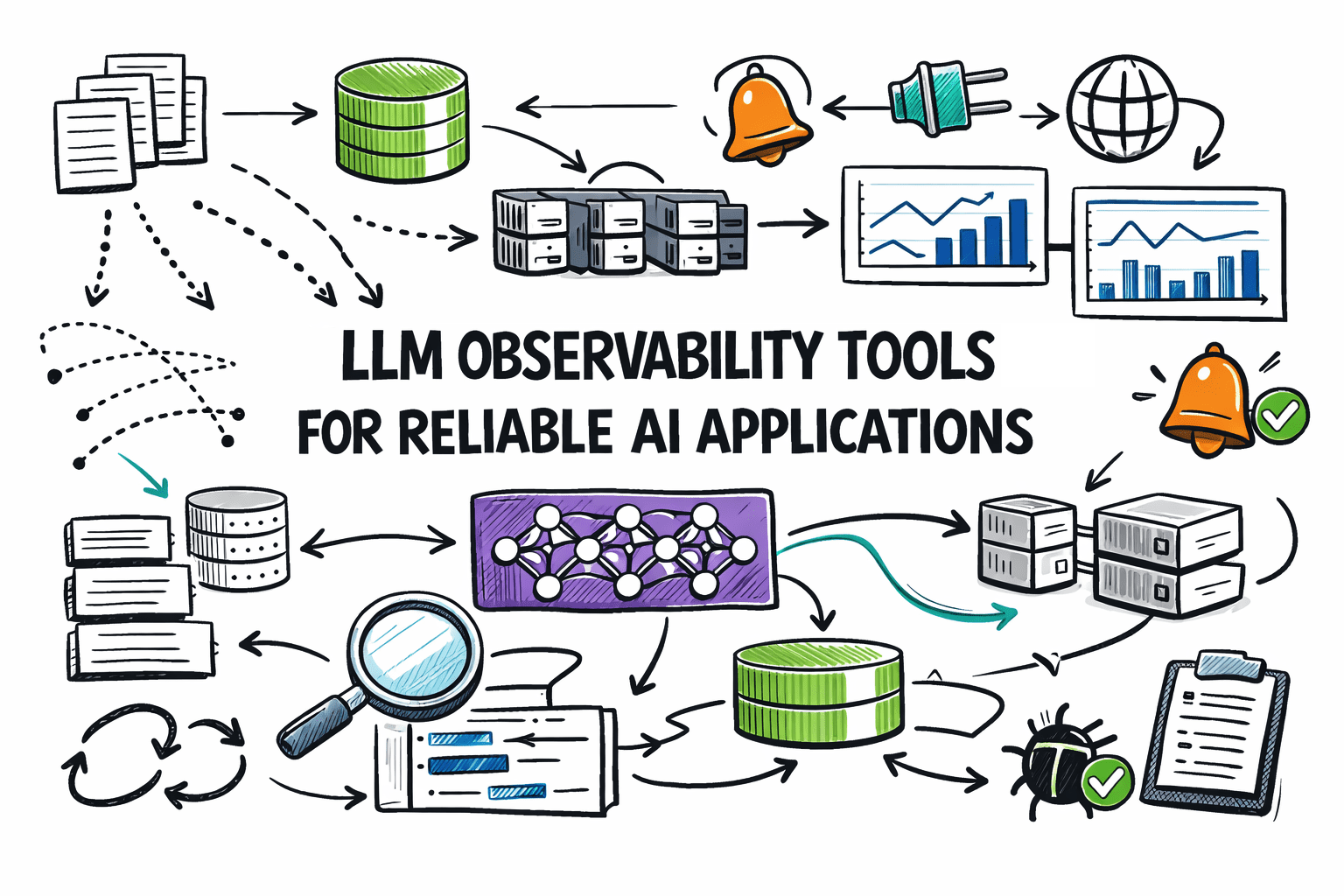
In this article, you will learn about seven leading LLM observability tools that help AI engineers monitor, evaluate, and debug large language model applications running in production.
CBSE earlier stated that it expects a significantly compressed timeline. By moving to the OSM Onmark portal, the Board aims to finish evaluation in roughly 9 days (down from the traditional 12-day cycle) and well ahead of the previous 60-day total window.