🖼️
0
0
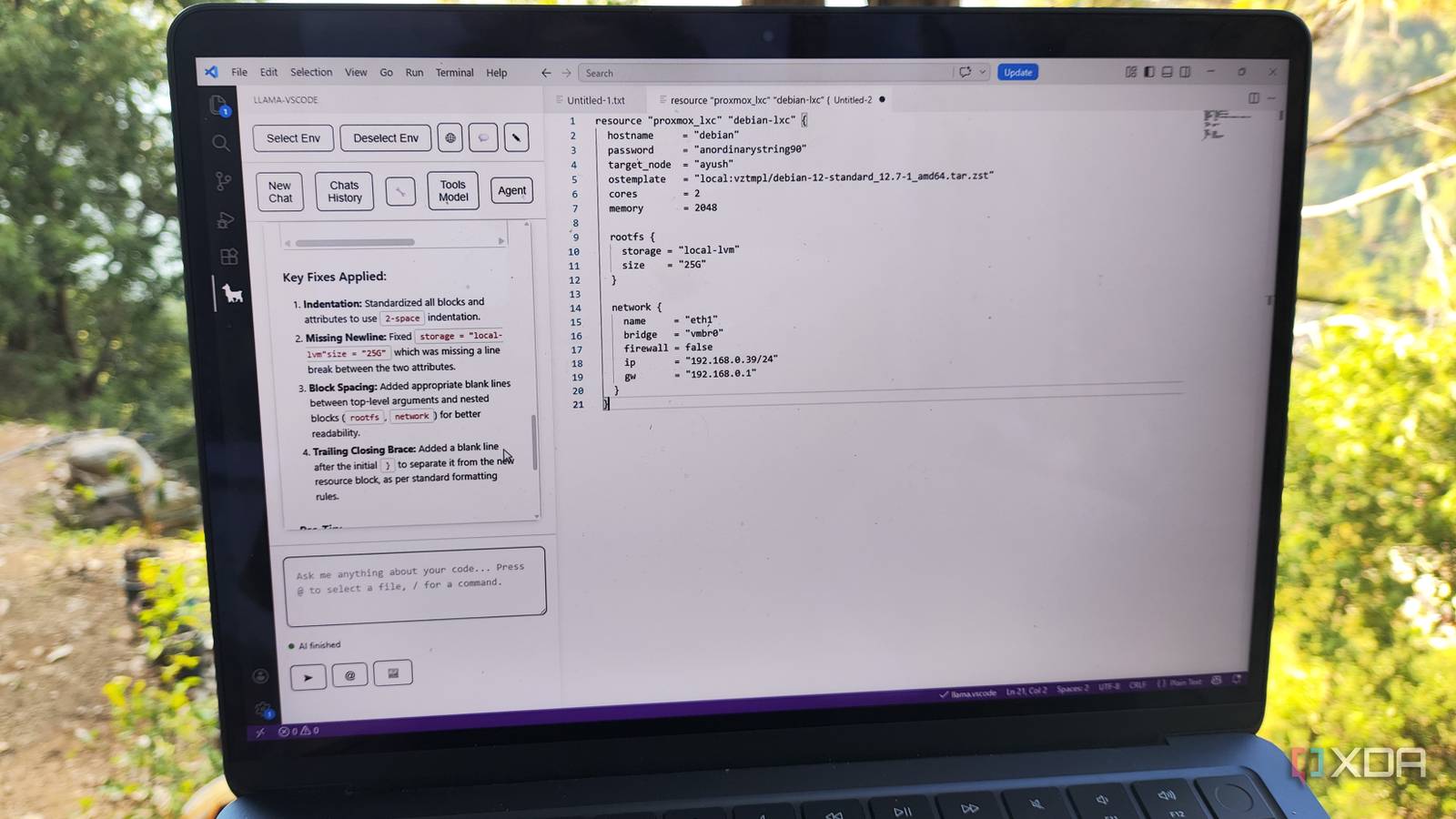
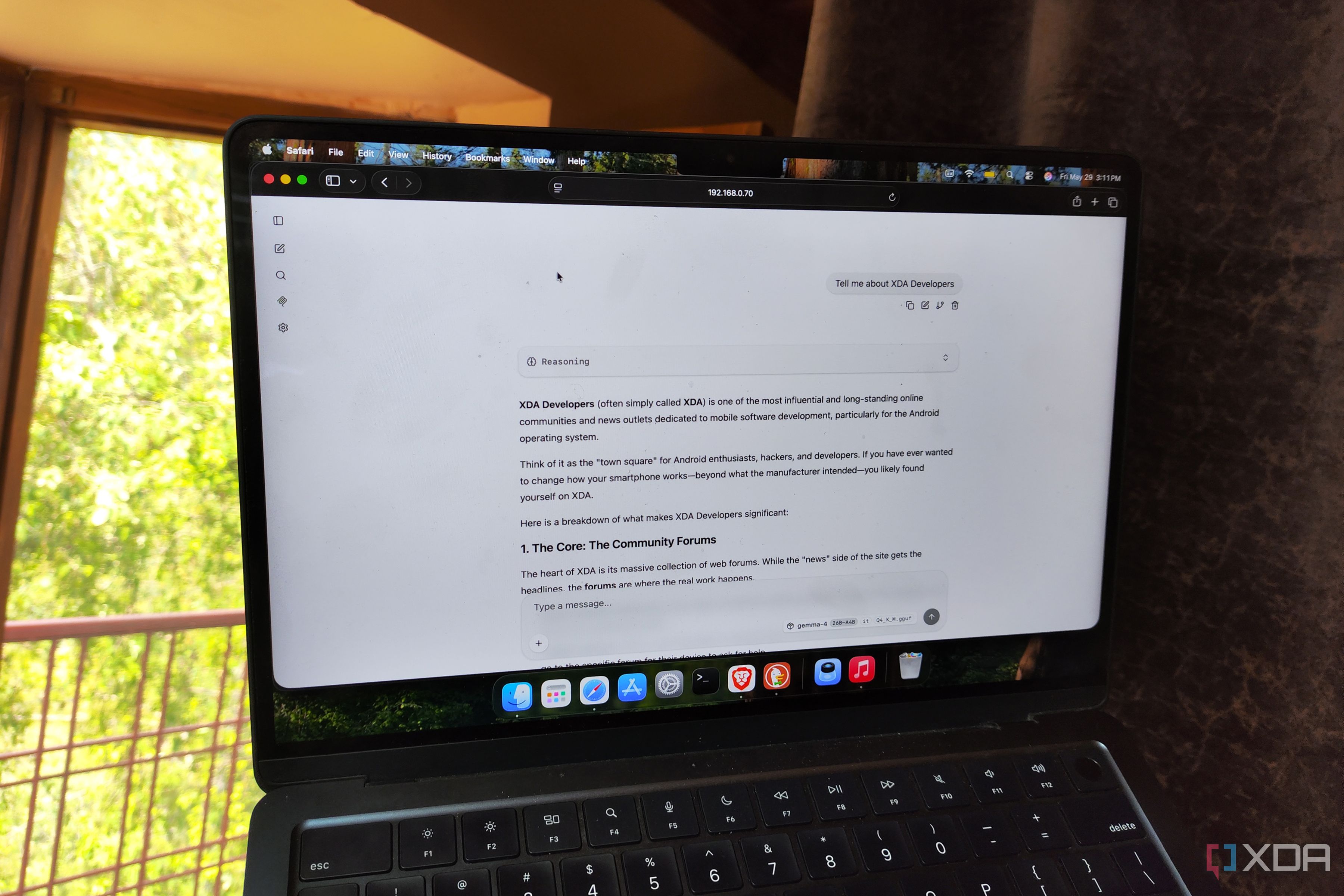
I replaced cloud LLMs with local models running off a Proxmox LXC, and the performance trade-off was worth it
View the full article
Create a free account to read full articles inline — no redirect to the original site.
86 posts
View the full article
Create a free account to read full articles inline — no redirect to the original site.