🖼️
227 posts

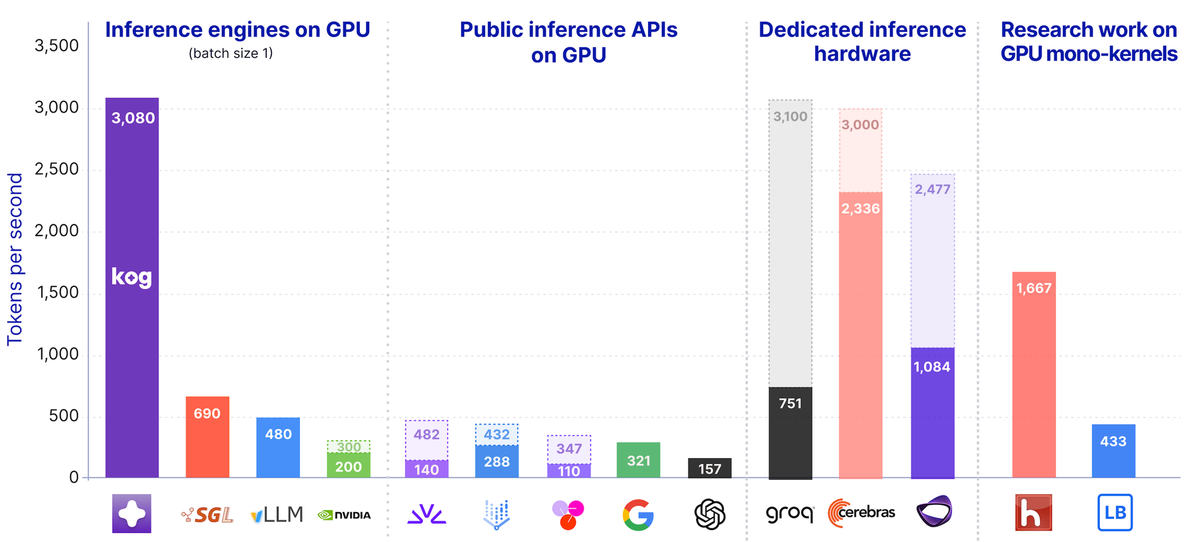
View the full article
Create a free account to read full articles inline — no redirect to the original site.


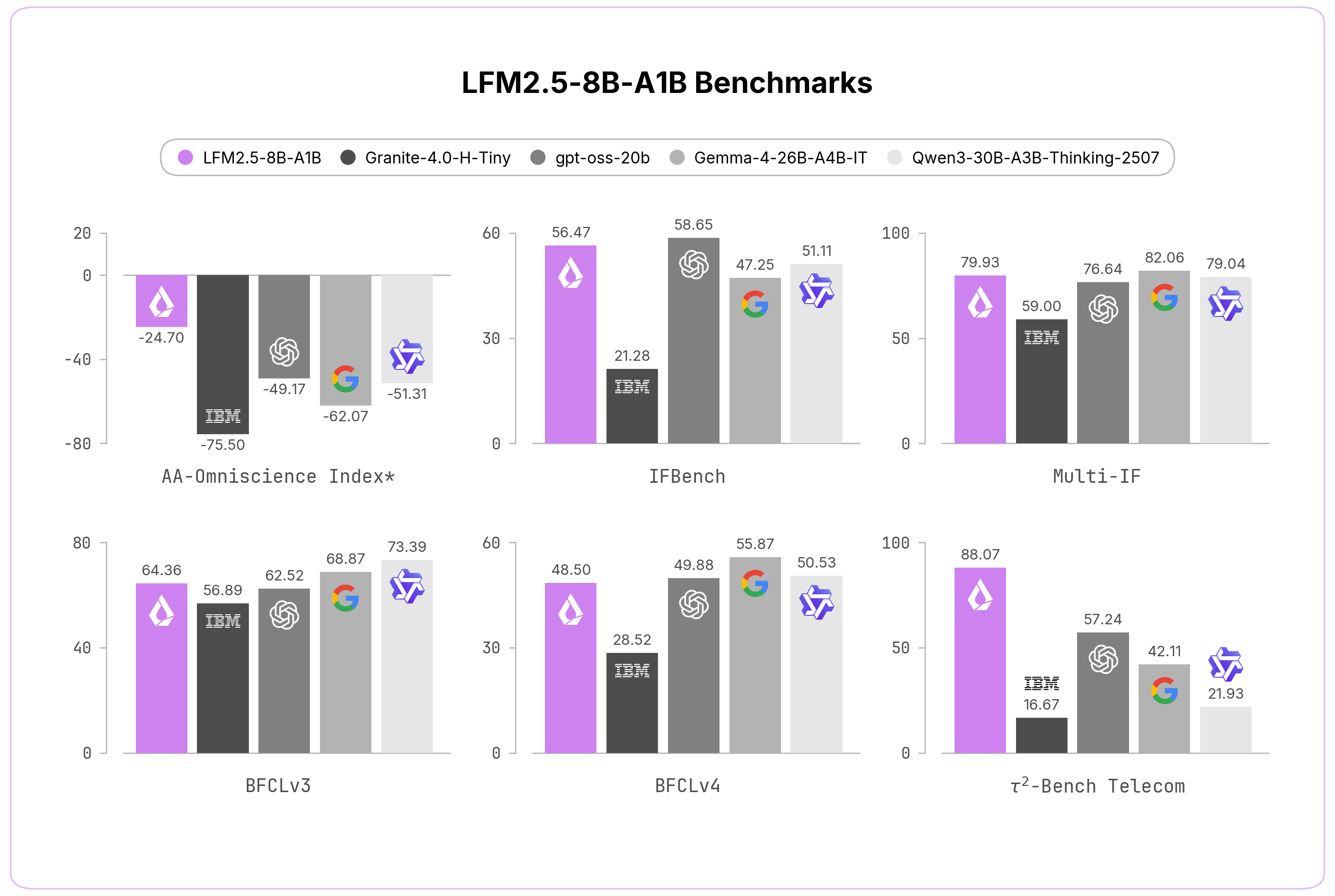

View the full article
Create a free account to read full articles inline — no redirect to the original site.



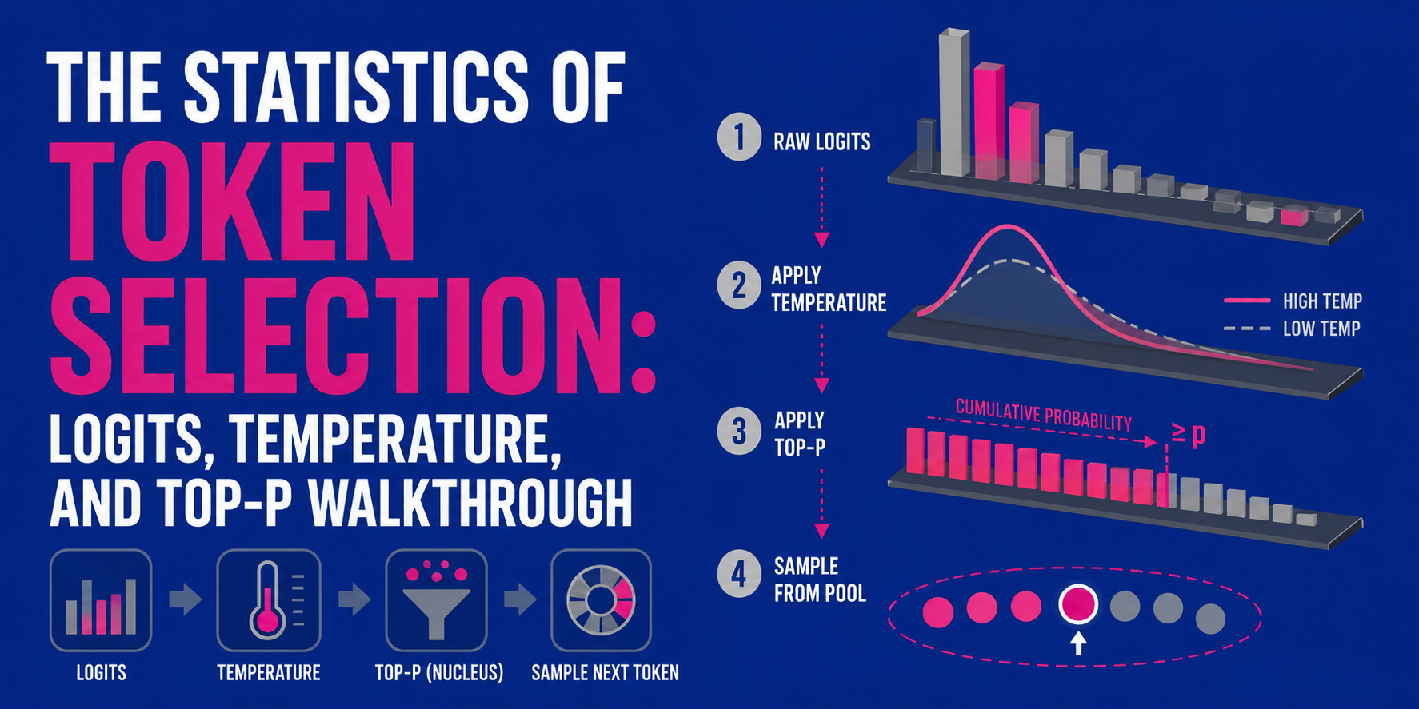

View the full article
Create a free account to read full articles inline — no redirect to the original site.