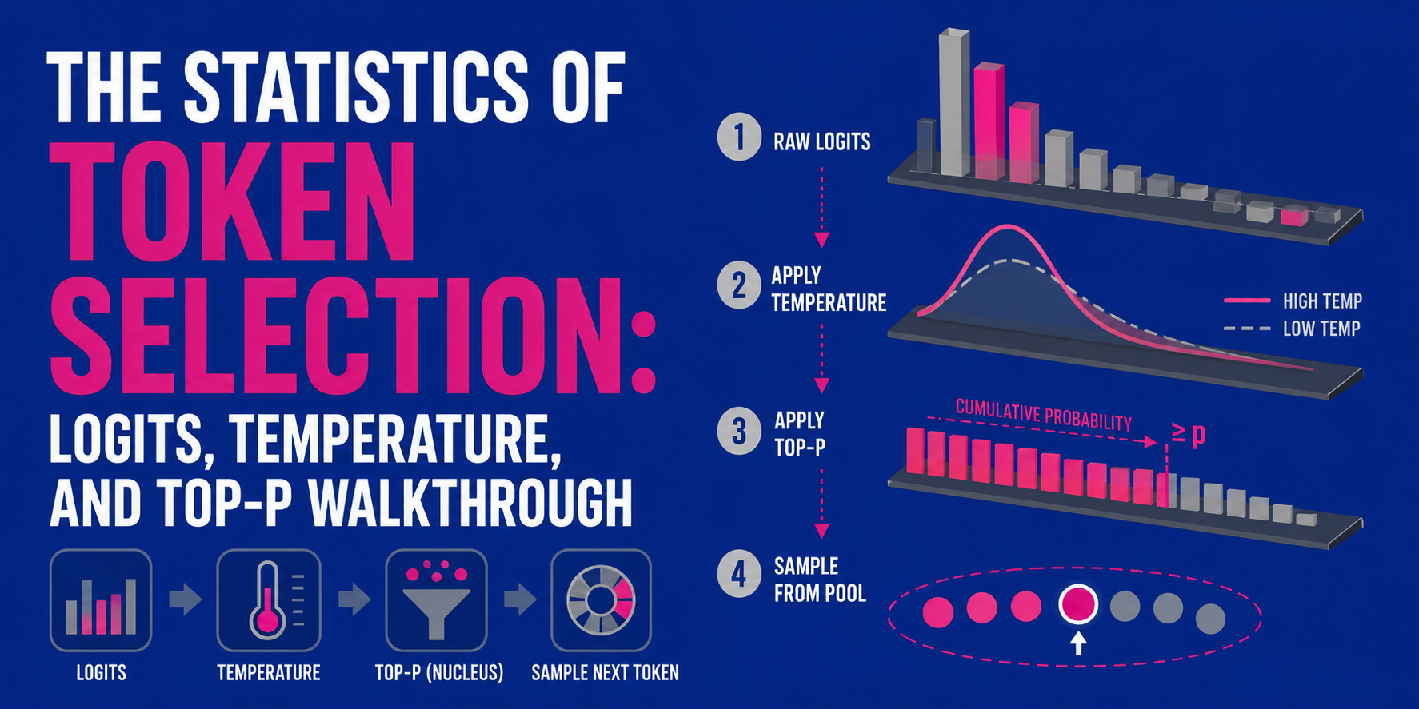
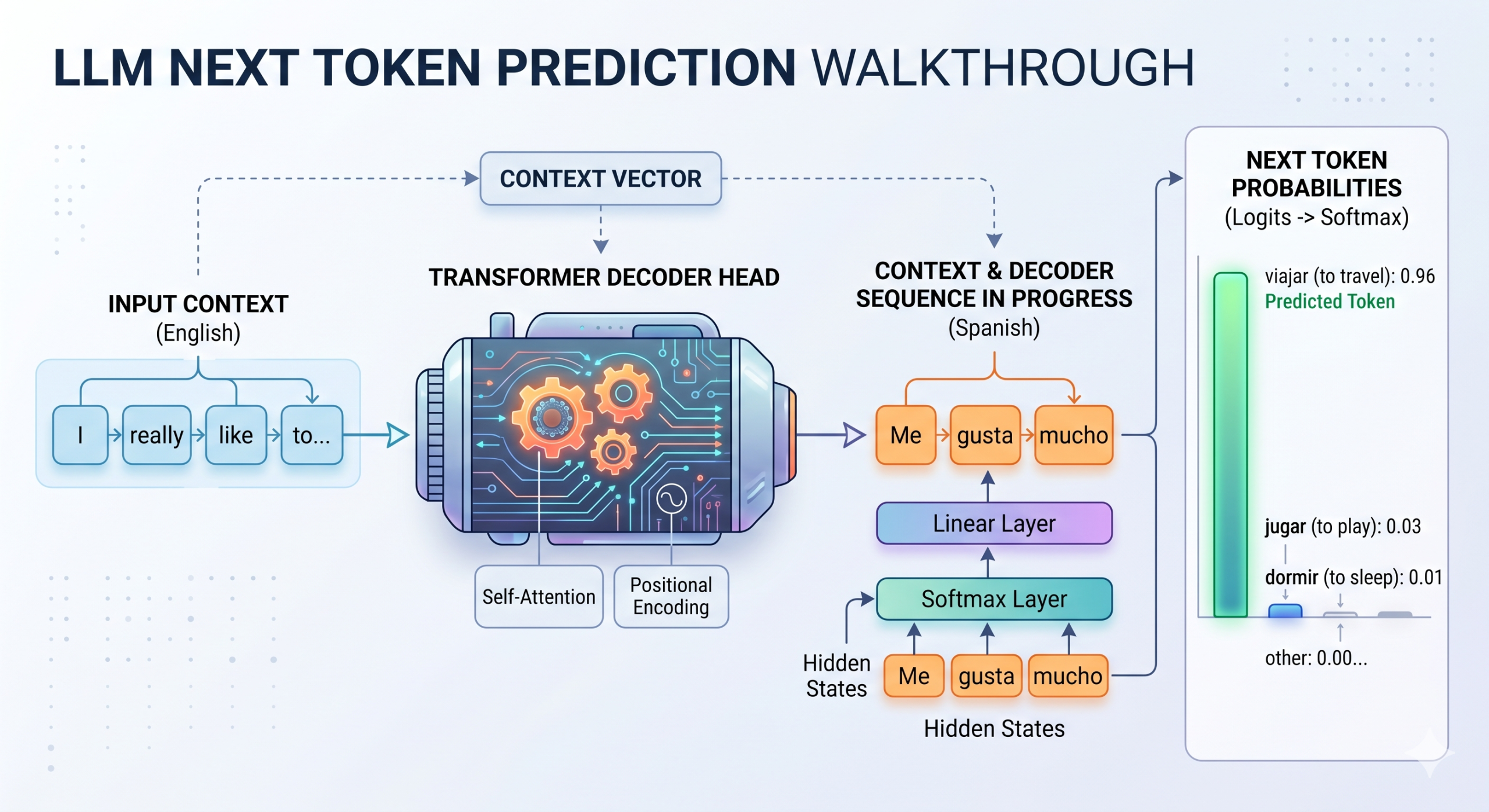
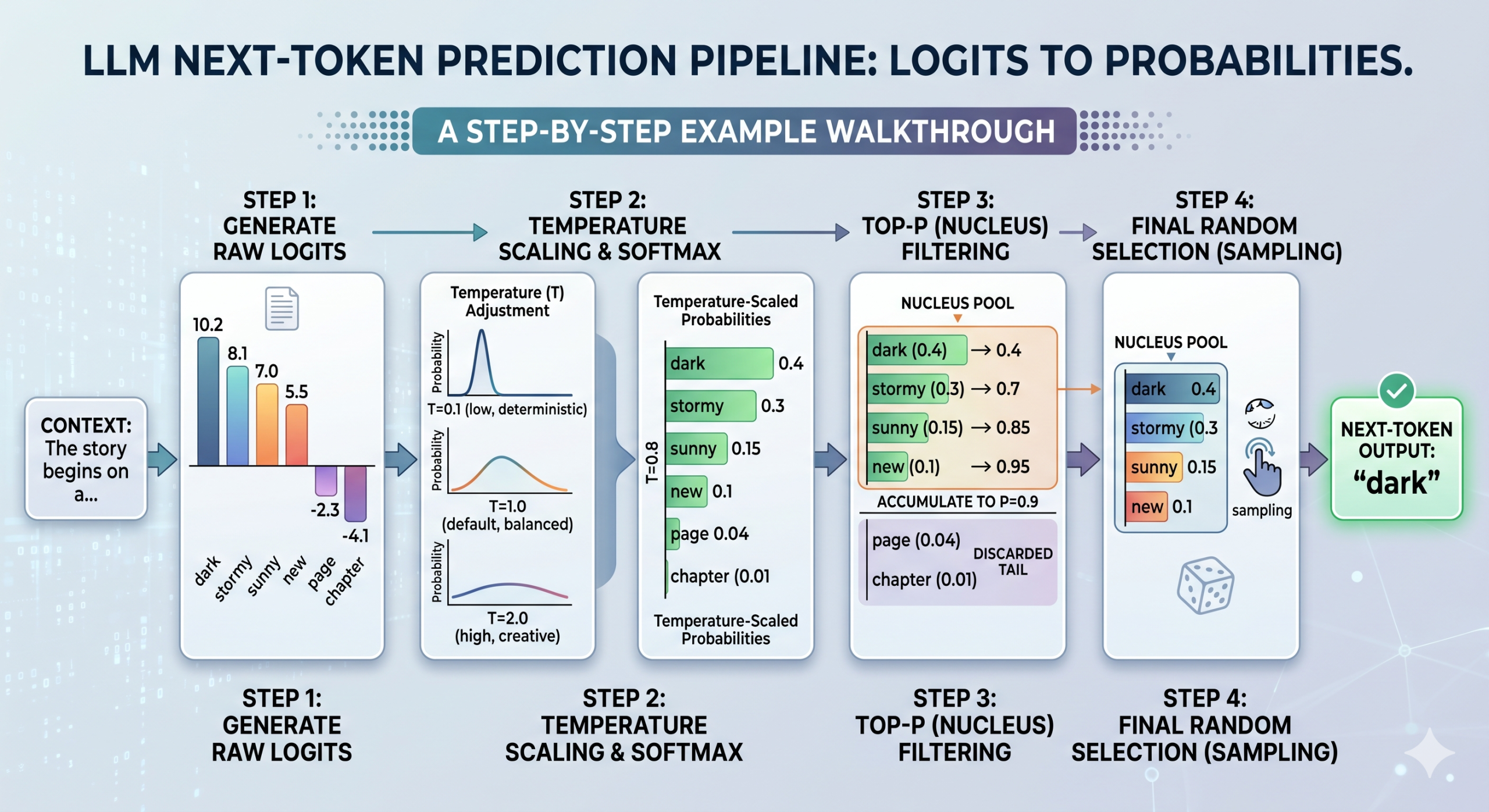
In this article, you will learn how logits, temperature, and top-p sampling work together to control next-token prediction in large language models. Topics we will cover include: What logits are and how they are produced by a transformer’s final linear layer. How temperature and top-p (nucleus sampling) shape the probability distribution used for token selection. How these three components fit into a sequential pipeline that governs LLM output generation. The Statistics of Token Selection: Logits, Temperature, and Top-P Walkthrough Introduction When large language models, or LLMs for short, produce outputs, several criteria are at stake, including not only overall response relevance but also coherence and creativity. Since deep inside the models operate by building their response word by word — or more precisely, token by token — capturing these desirable properties is a matter of mathematically adjusting the output probability distributions that govern the next-token prediction process.…