
1 / 5
0
0
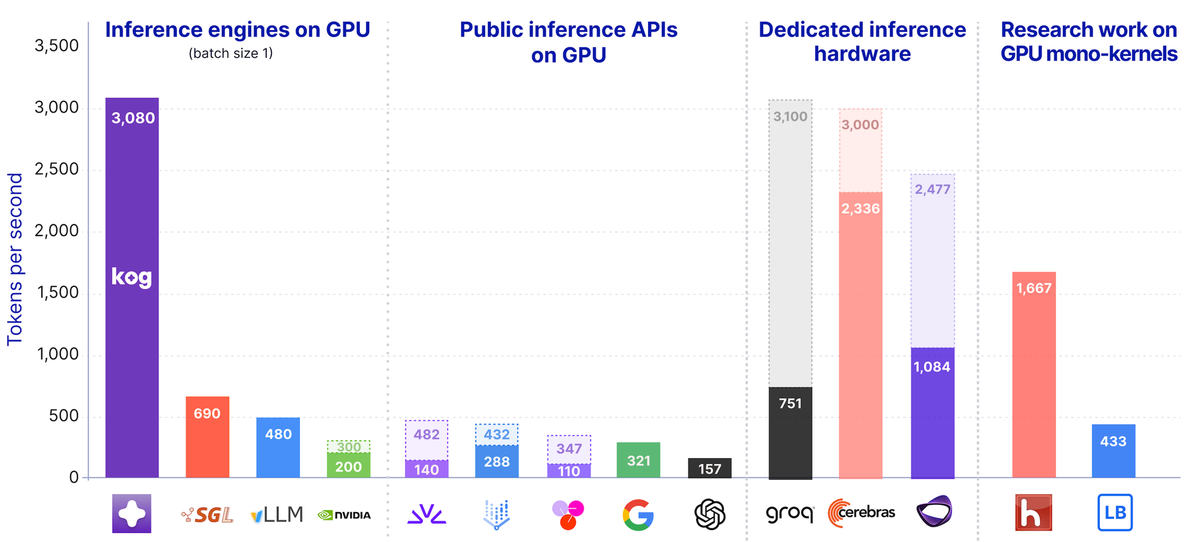
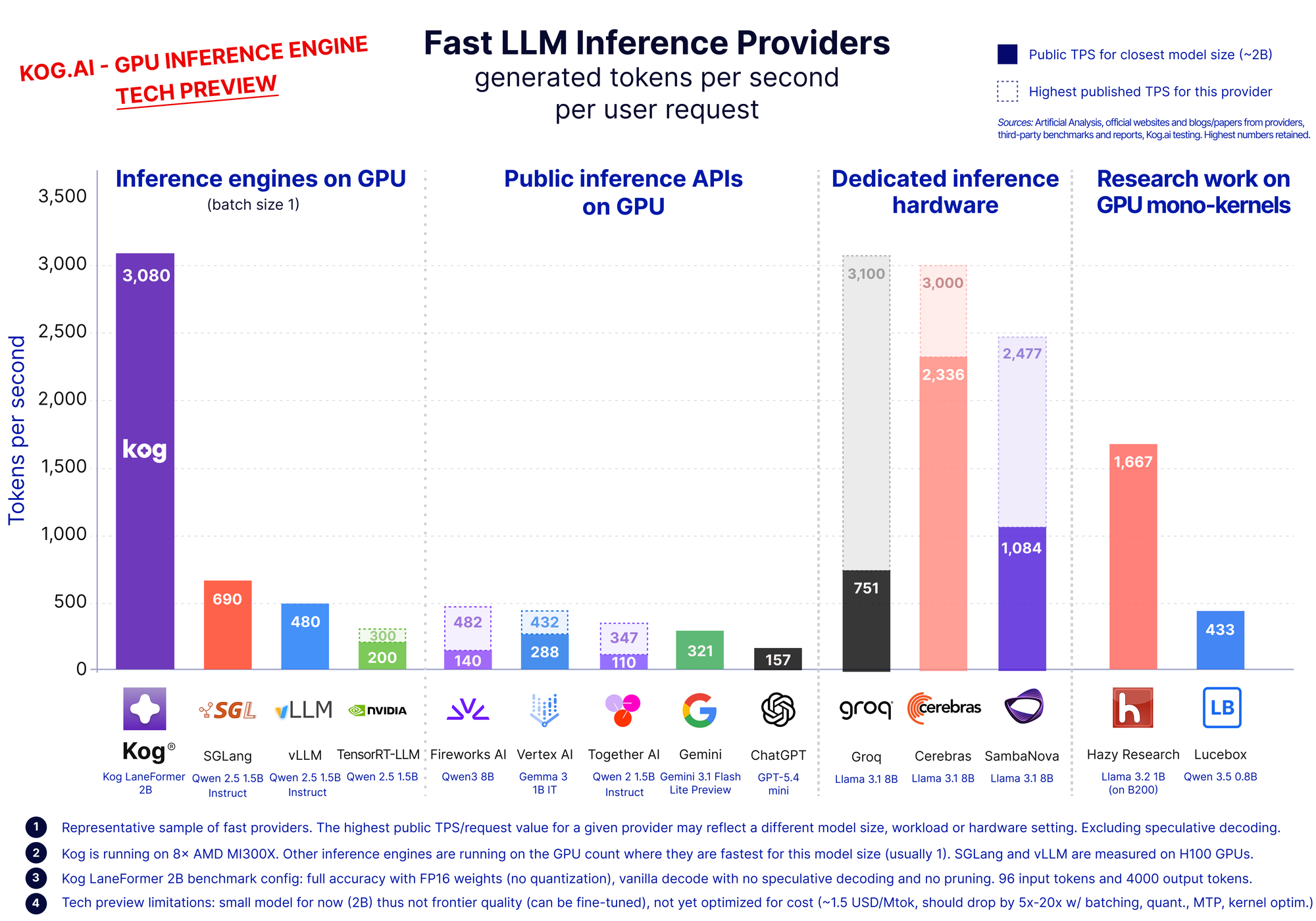
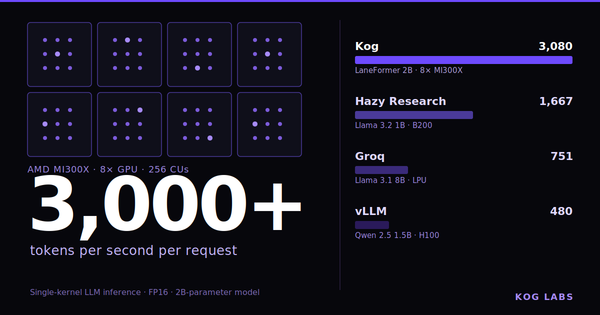
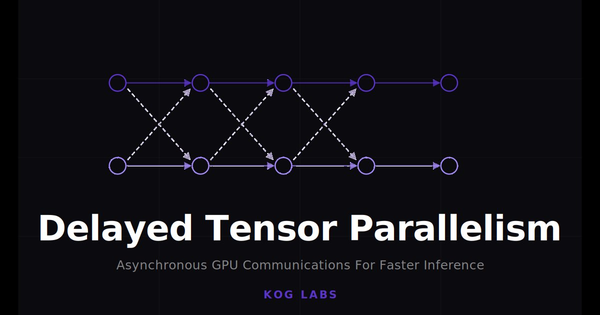
Real-time LLM Inference on Standard Datacenter GPUs (3,000 tokens/s per request)
Hacker News·Real-time LLM Inference on Standard Datacenter GPUs (3,000 tokens/s per request)·3 days ago
#s5bKajPnReading 0:0015s threshold
Continue reading — create a free account
Join HashtagPLUS to read full articles, follow hashtags, vote, and join the conversation.