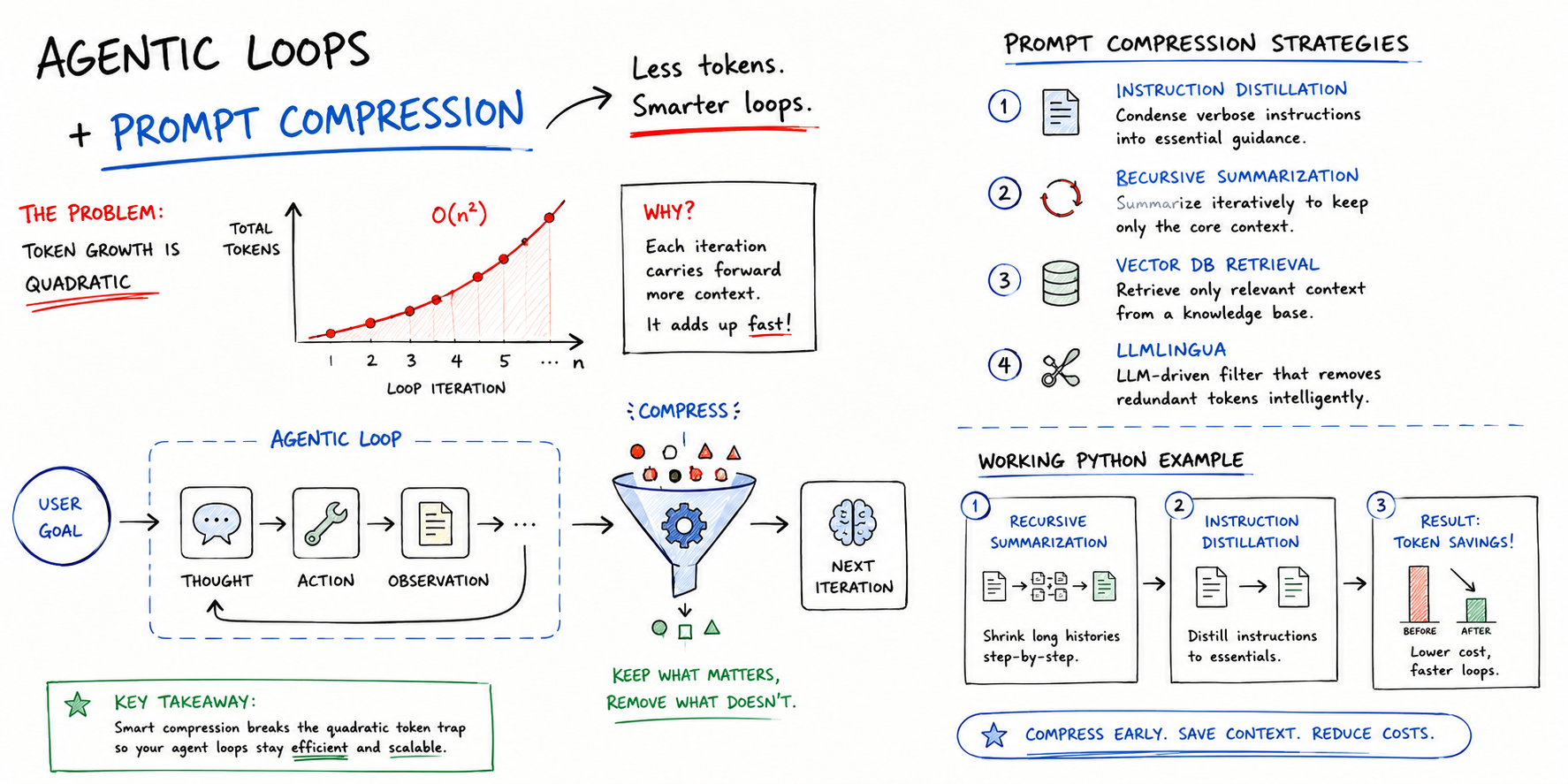
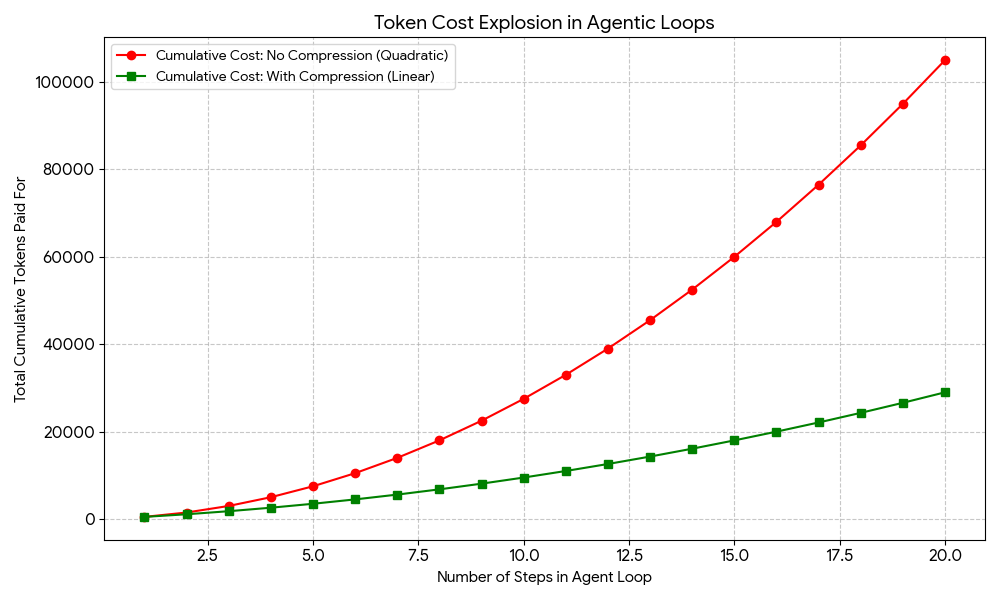
In this article, you will learn what prompt compression is, why it matters for agentic AI loops, and how to implement it practically using summarization and instruction distillation. Topics we will cover include: Why agentic loops accumulate token costs quadratically, and how prompt compression addresses this. A review of the main prompt compression strategies, including instruction distillation, recursive summarization, vector database retrieval, and LLMLingua. A working Python example that combines recursive summarization and instruction distillation to achieve meaningful token savings. Introduction Agentic loops in production can be synonymous with high costs, especially when it comes to both LLM and external application usage via APIs, where billing is often closely related to token usage. The good news: prompt compression is one of the most effective strategies you can implement to navigate the high costs of agentic loops.…