You can now access Qwen3 Coder, a model from QwenLM, an Alibaba Cloud company, designed to handle complex, multi-step coding workflows, using Vercel's AI Gateway with no other provider accounts required.
You can now access Qwen3 Next, two models from QwenLM, designed to be ultra-efficient, using Vercel's AI Gateway with no other provider accounts required.
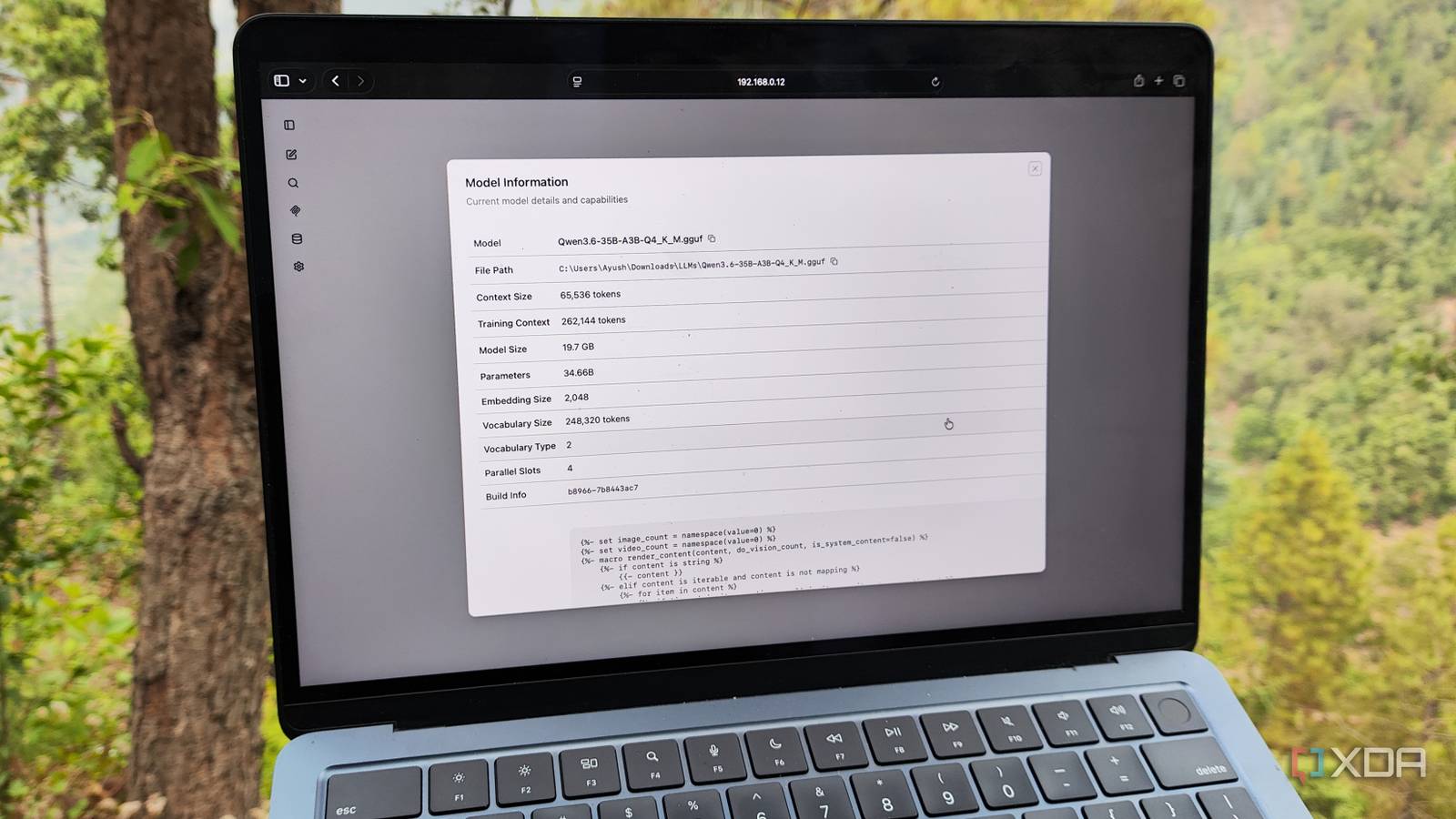
Alibaba has introduced the new open source Qwen3.5 series built for native multimodal agents. The first model in this series is a ~400B parameter native vision…