At 620 million monthly users, calling a frontier model for every image recommendation isn't a strategy — it's a bill. Pinterest CTO Matt Madrigal solved it by gutting Qwen3-VL's vision layer and rebuilding it with proprietary embeddings, cutting costs 90%…
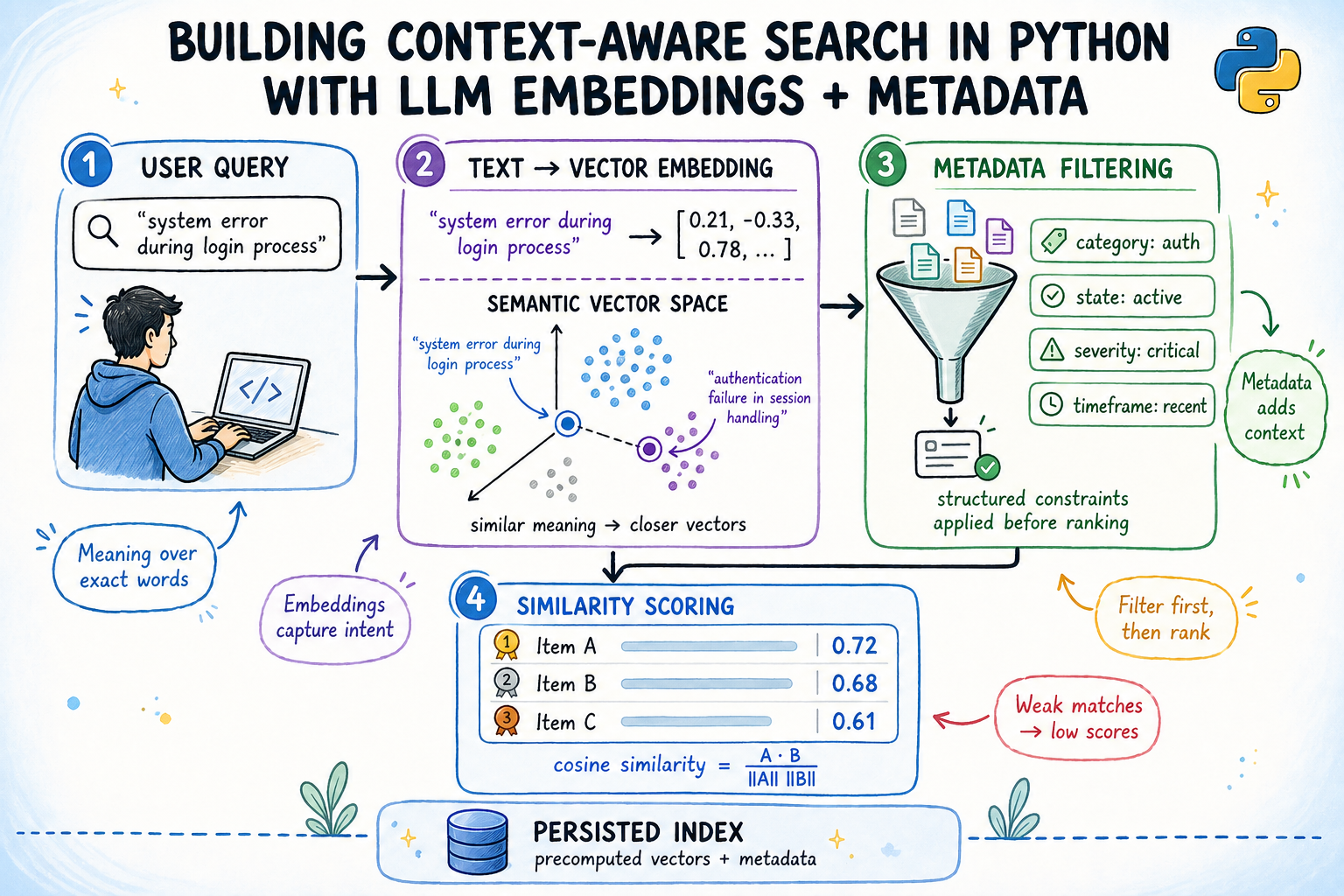
In this article, you will learn how to build a context-aware semantic search engine in Python that combines embedding-based similarity with structured metadata filtering.
Explore vector embeddings, their function in AI, types like Word2Vec and BERT, applications in semantic search and NLP, and implementation considerations for de
Hey everyone, I have been digging into vector databases, ANN search, and privacy preserving techniques (specifically PHE), and I have hit a design roadblock that I would love some input on.…