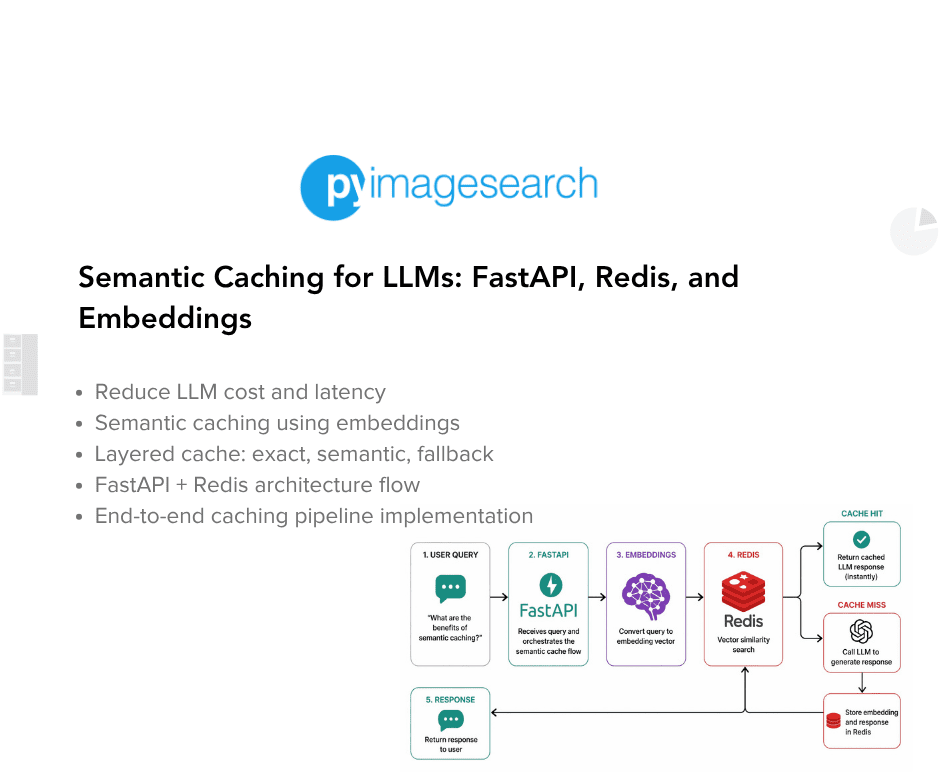
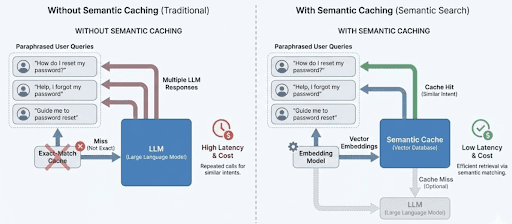
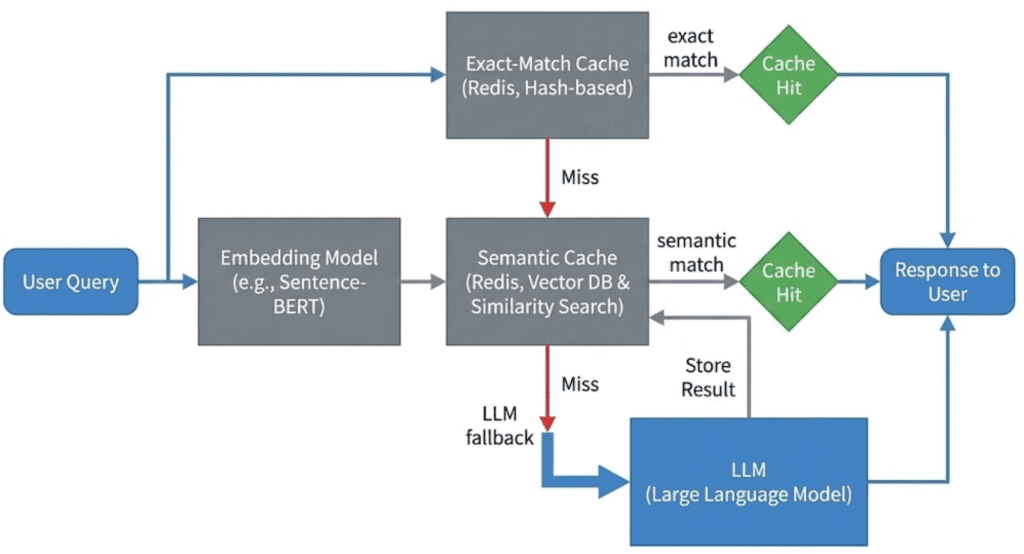
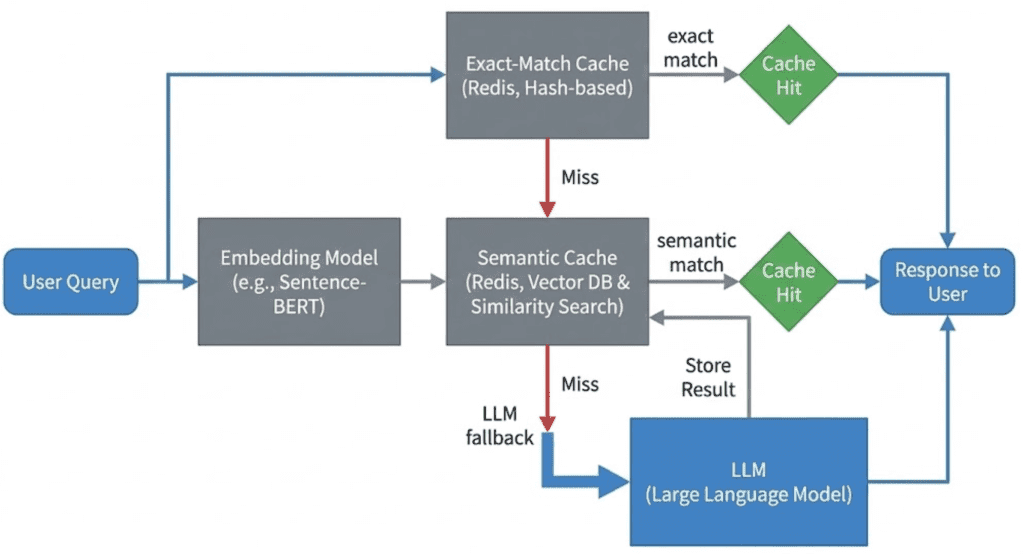
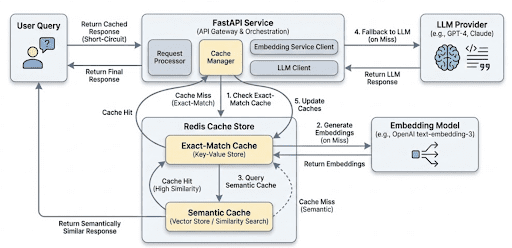
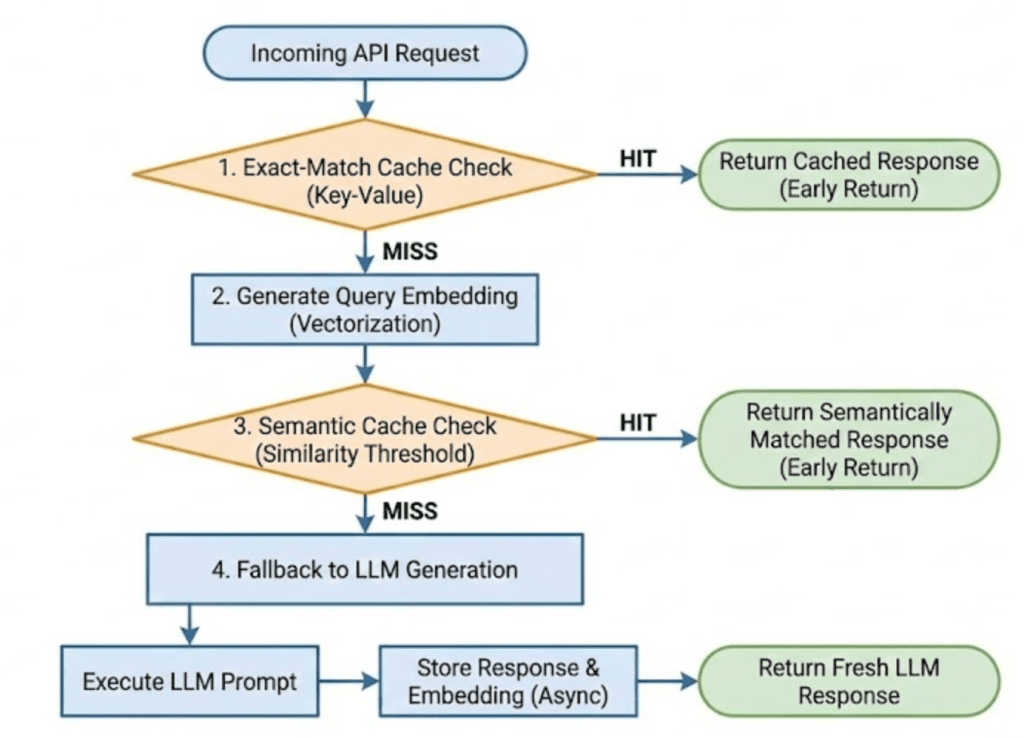
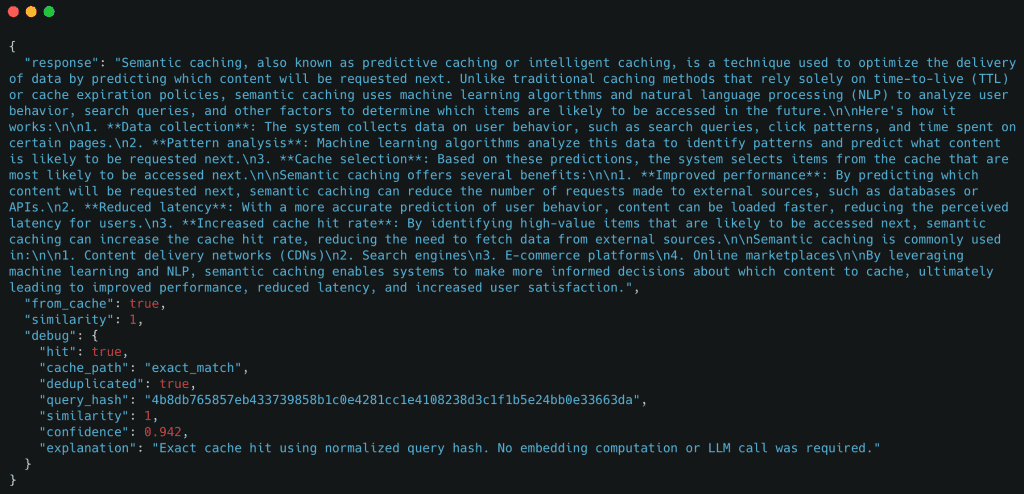
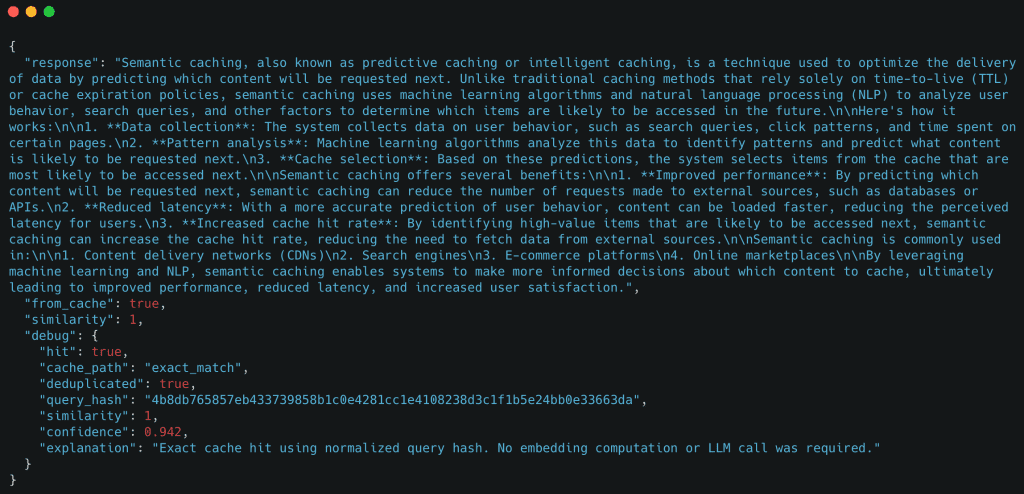
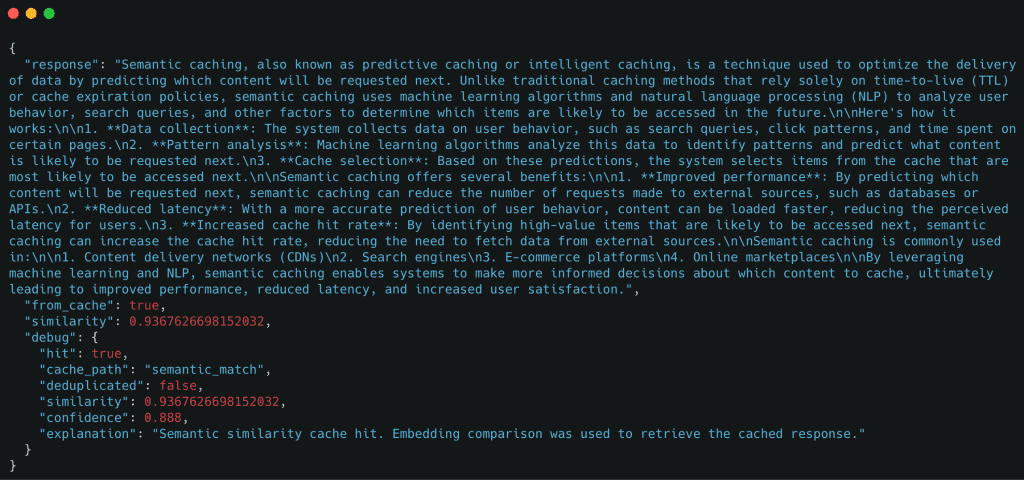
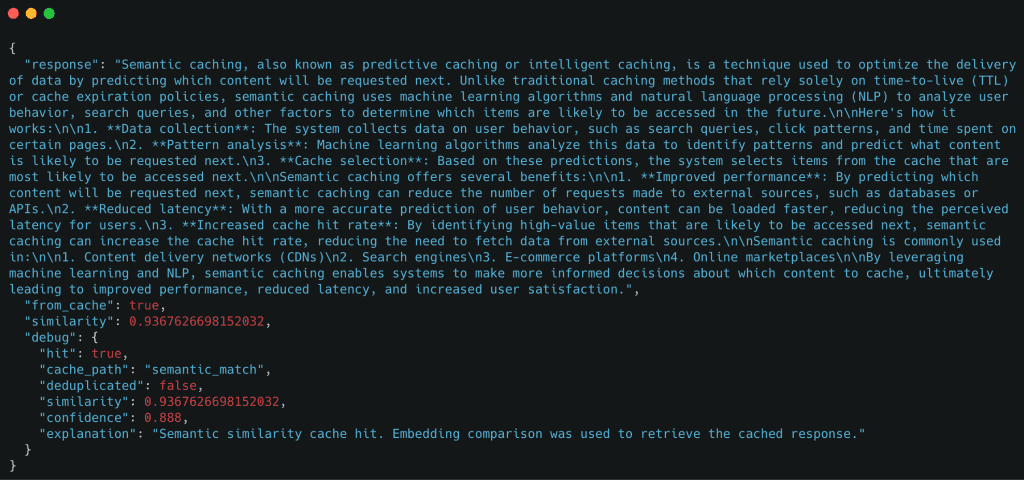
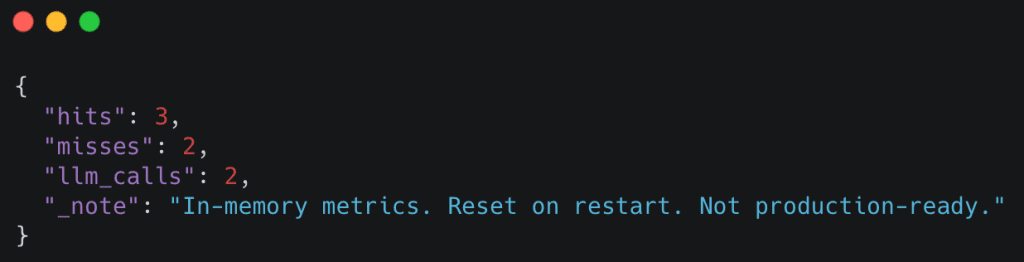
Table of Contents Semantic Caching for LLMs: FastAPI, Redis, and Embeddings Introduction: Why Semantic Caching Matters for LLM Systems How Semantic Caching Works for LLMs: Embeddings and Similarity Search Explained Semantic Caching Architecture and Request Flow Configuring Your Environment for Semantic Caching: FastAPI, Redis, and Ollama Setup Project Structure FastAPI Entry Point for Semantic Caching: Wiring the API Service FastAPI Ask Endpoint: End-to-End Semantic Caching Request Flow Embeddings: Turning Text into Semantic Vectors The Semantic Cache: Cosine Similarity, Redis Storage, and Reusing Meaning Cache Entries: What Exactly Gets Stored? End-to-End Demo: Verifying Core Cache Behavior Summary In this lesson, you will learn how to build a semantic cache for LLM applications using FastAPI, Redis, and embedding-based similarity search, and how requests flow from exact matches to semantic matches before falling back to the LLM.…