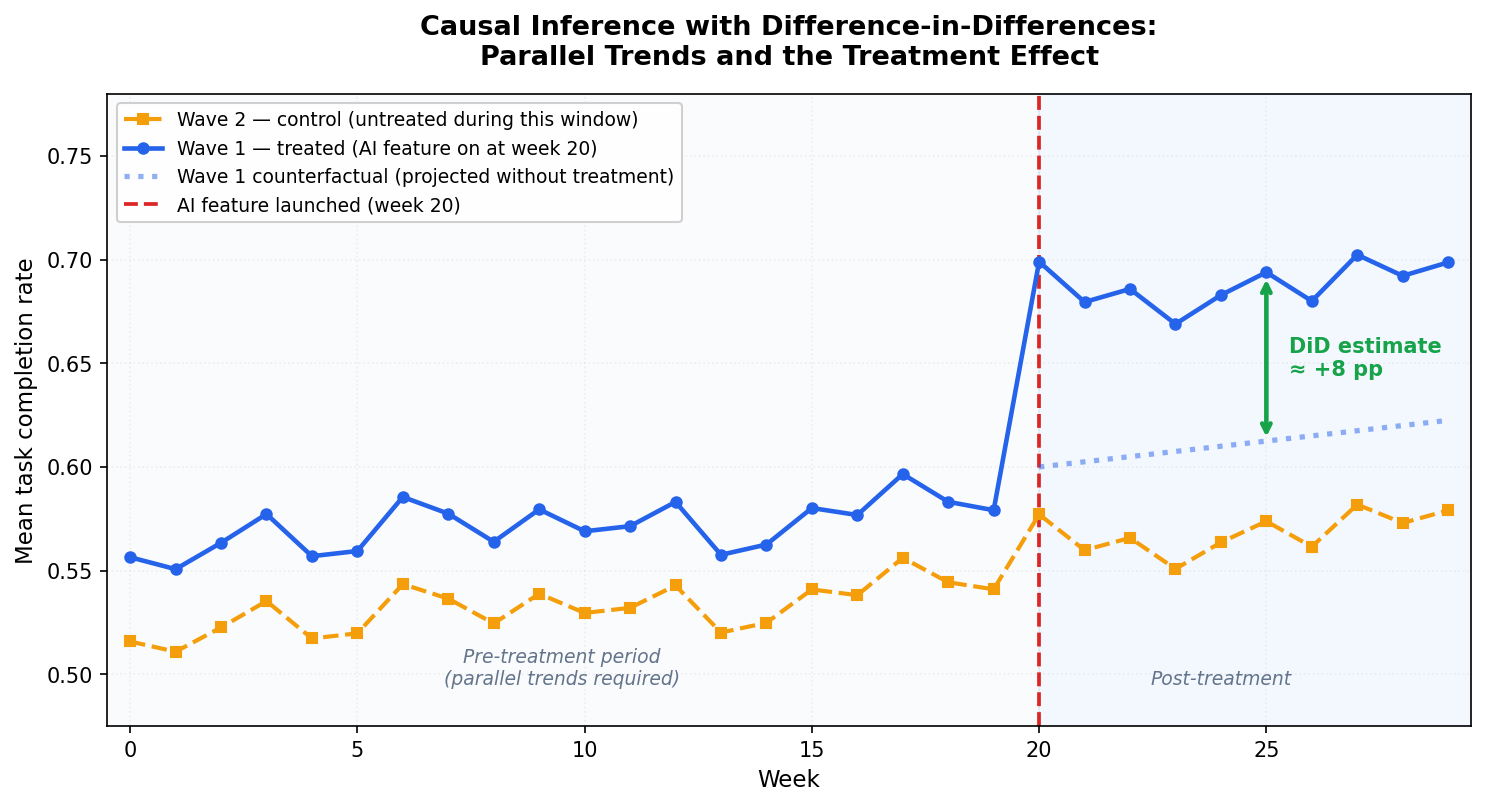
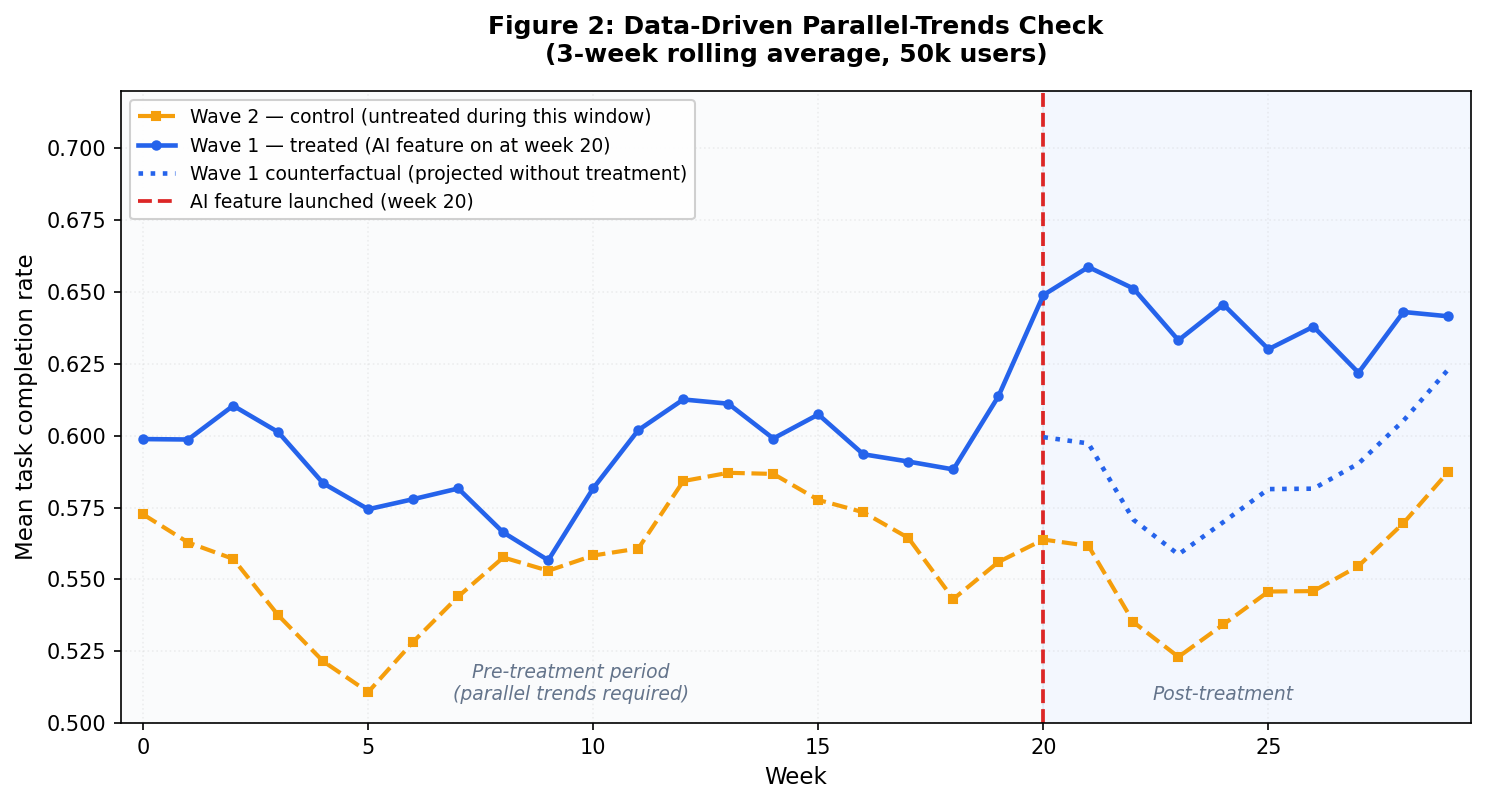
Your team shipped an LLM-based summaries feature to wave 1 workspaces at week 20 and now the post-launch doc is due. You need a causal effect number, a specific estimate you can defend to a statistician. The problem is that wave 2 workspaces are still waiting, a product-wide onboarding redesign shipped the same Tuesday, and week 20 also coincided with a quarterly engagement bump. Any comparison between the two groups after week 20 mixes the feature's causal effect with the redesign, the seasonality, and whatever selection criteria determined which workspaces landed in wave 1 in the first place. This is how most enterprise SaaS teams ship AI features in 2026: one workspace at a time, in waves, on a rollout calendar. Randomization doesn't happen, and because randomization doesn't happen, A/B testing can't give you a clean causal effect. The result is a number on a dashboard that everyone argues over.…