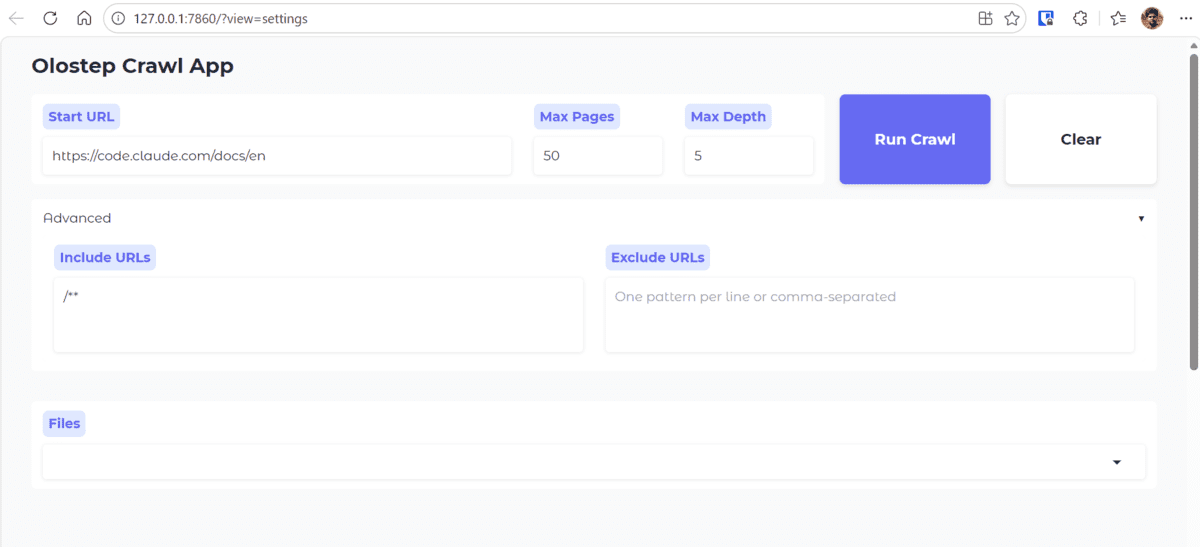
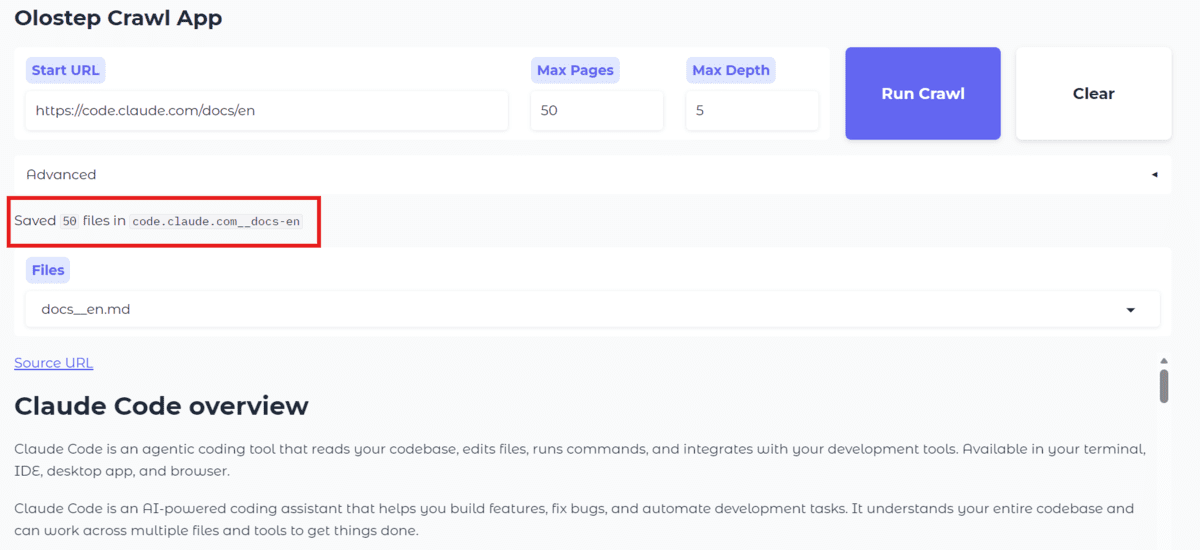
Image by Author # Introduction Web crawling is the process of automatically visiting web pages, following links, and collecting content from a website in a structured way. It is commonly used to gather large amounts of information from documentation sites, articles, knowledge bases, and other web resources. Crawling an entire website and then converting that content into a format that an AI agent can actually use is not as simple as it sounds. Documentation sites often contain nested pages, repeated navigation links, boilerplate content, and inconsistent page structures. On top of that, the extracted content needs to be cleaned, organized, and saved in a way that is useful for downstream AI workflows such as retrieval, question-answering, or agent-based systems.…