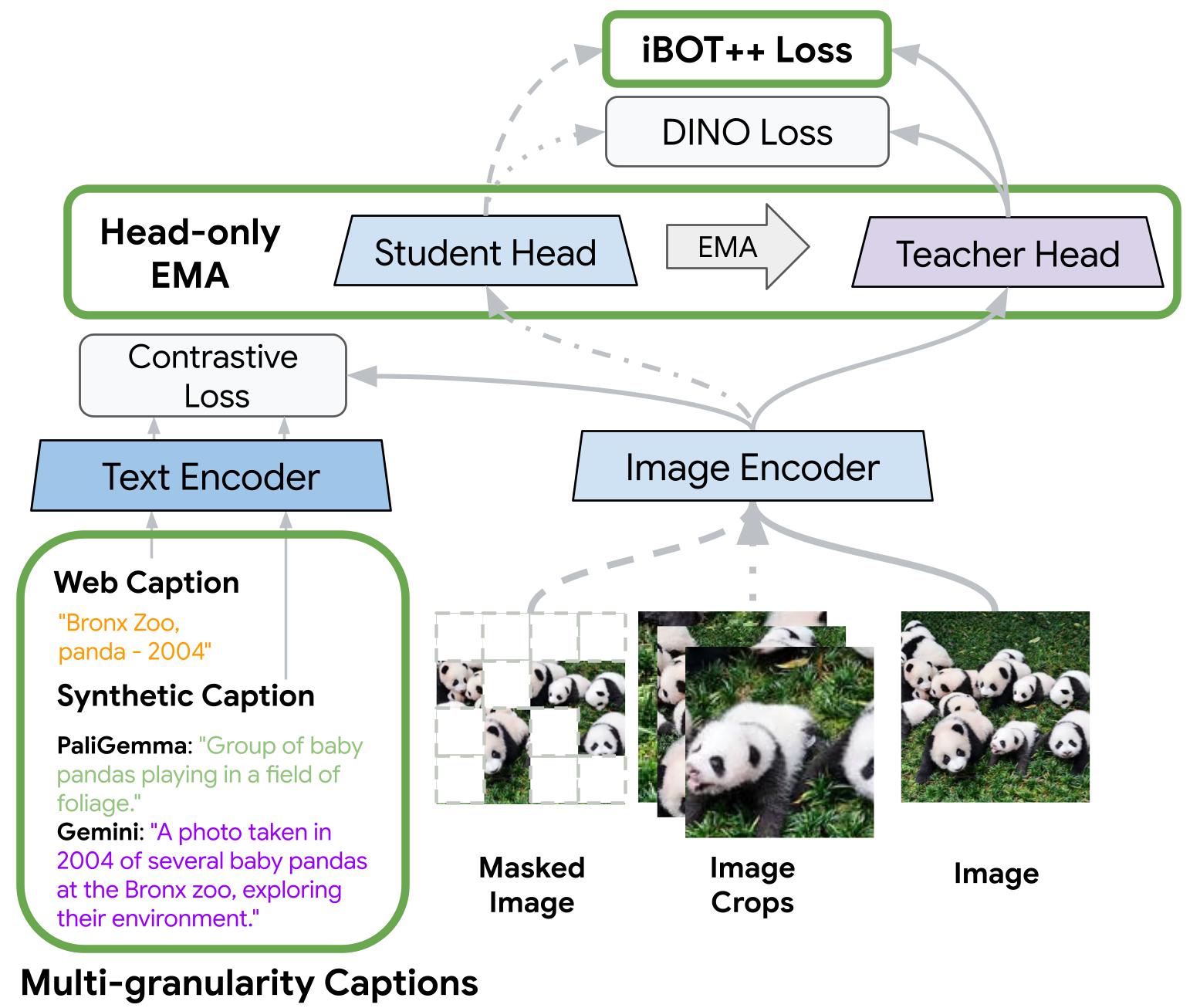
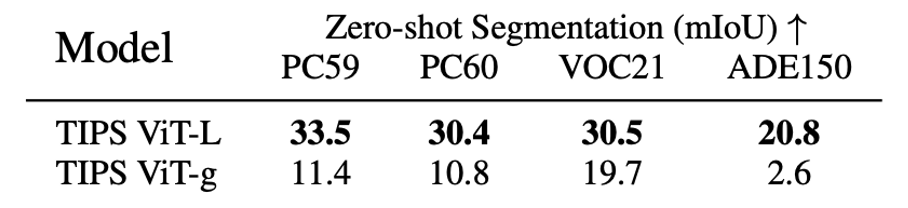
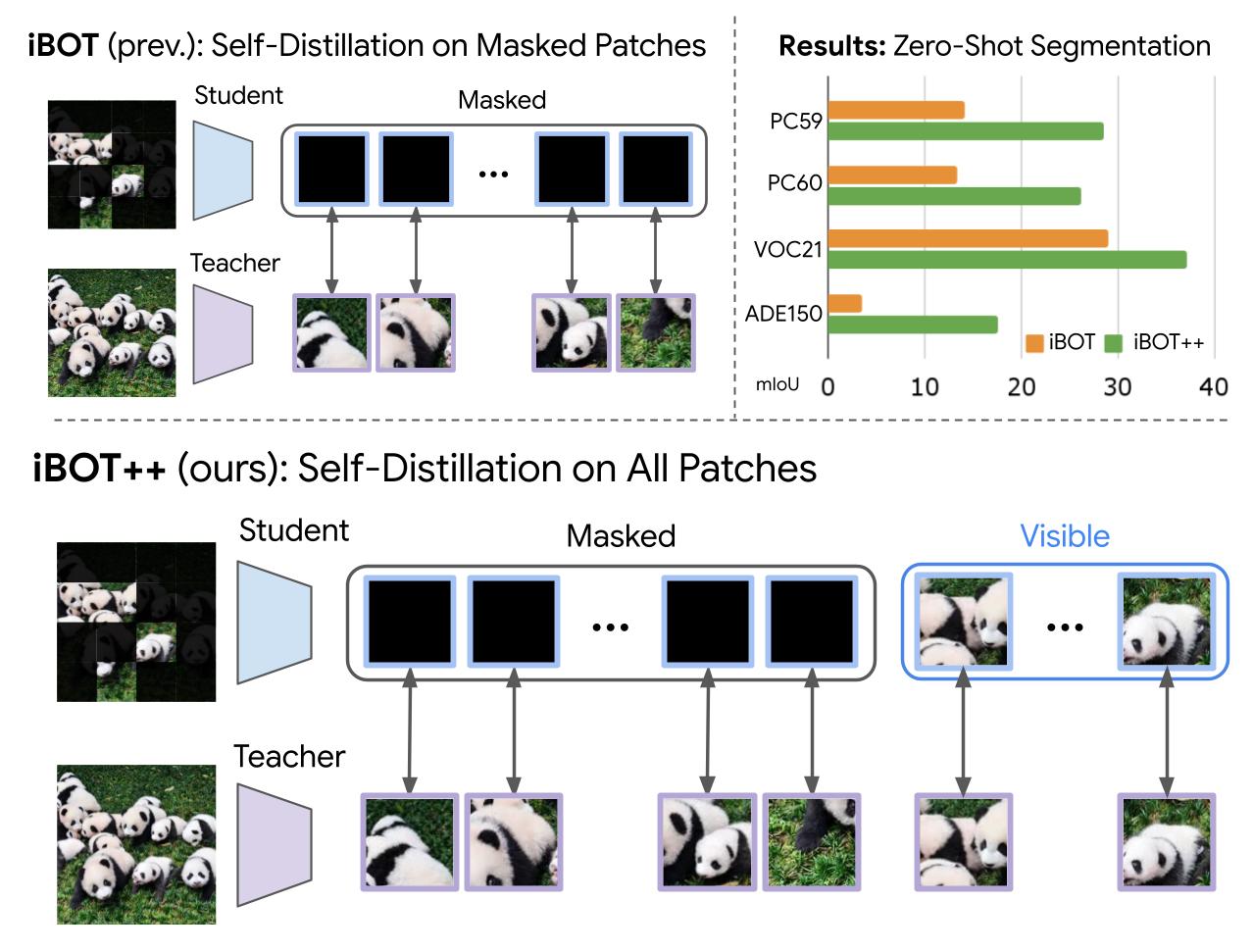
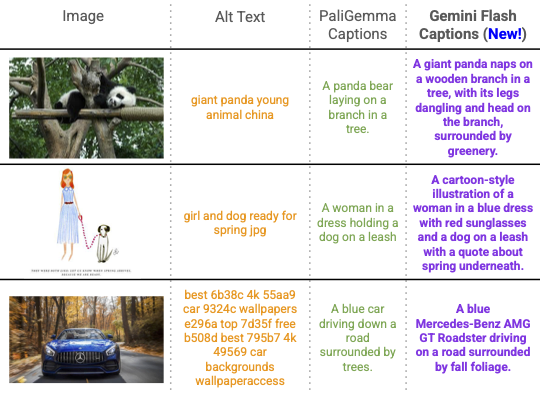
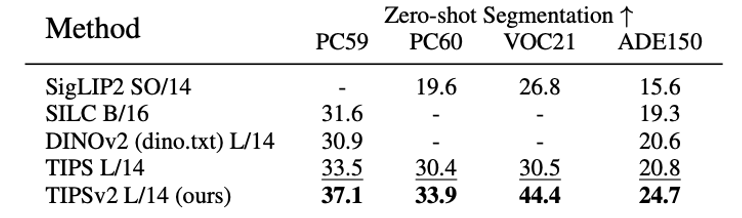
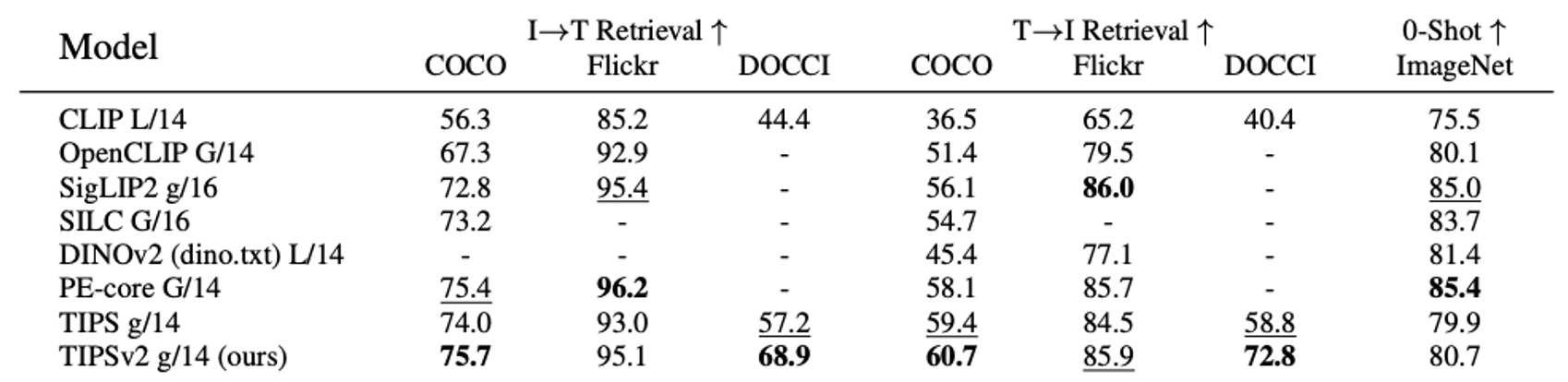
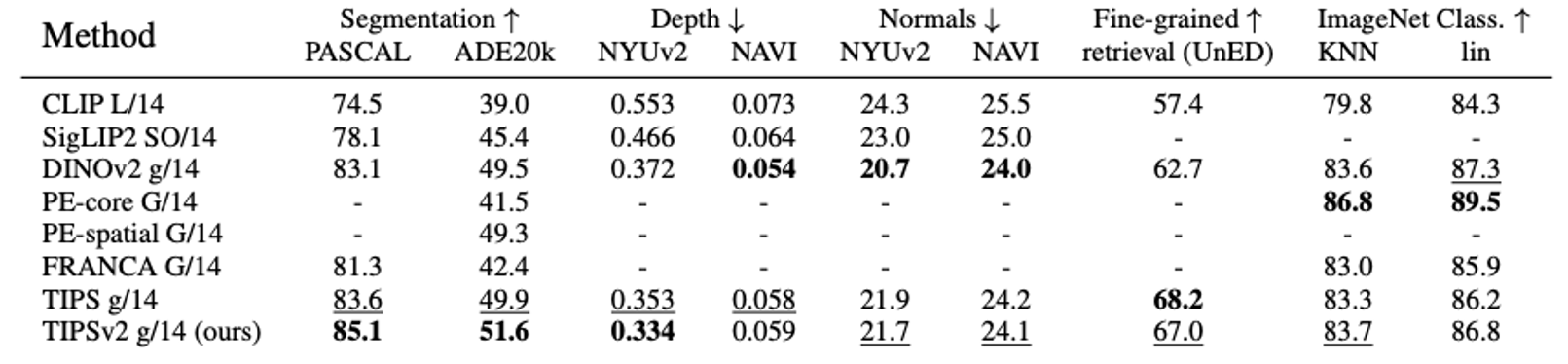
Google DeepMind * Equal contribution now at: 1 xAI 2 Epsilon Health 3 Seoul National University 4 Google CVPR 2026 Overview TIPSv2 is the next generation of the TIPS family of foundational image-text encoders empowering strong performance across numerous multimodal and vision tasks. Our work starts by revealing a surprising finding, where distillation unlocks superior patch-text alignment over standard pretraining, leading to distilled student models significantly surpassing their much larger teachers in this capability. We carefully investigate this phenomenon, leading to an improved pretraining recipe that upgrades our vision-language encoder significantly.…