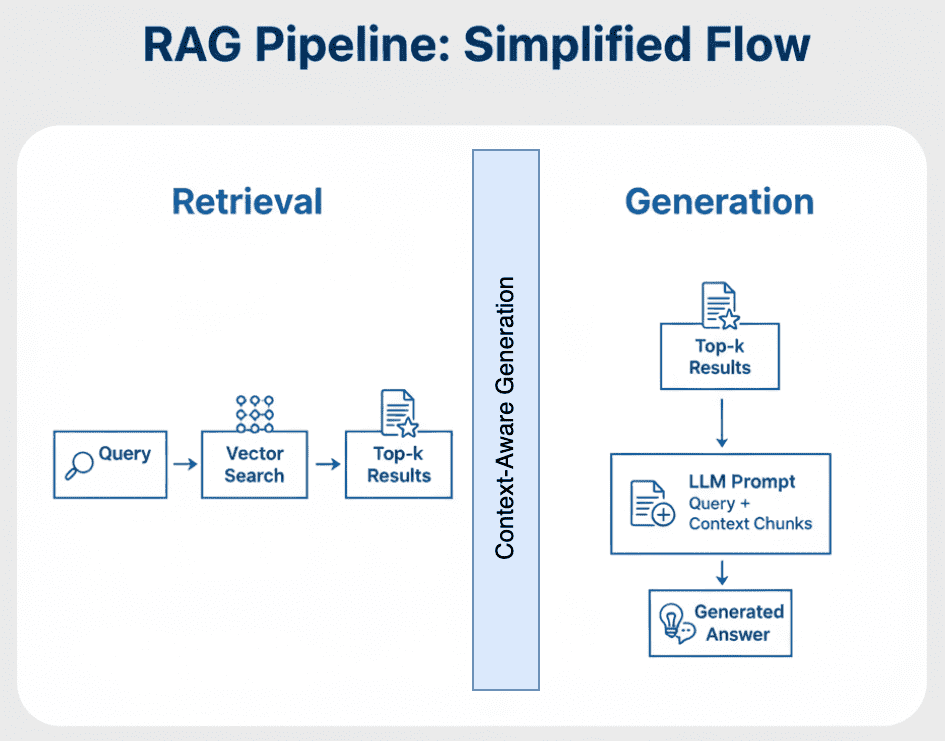
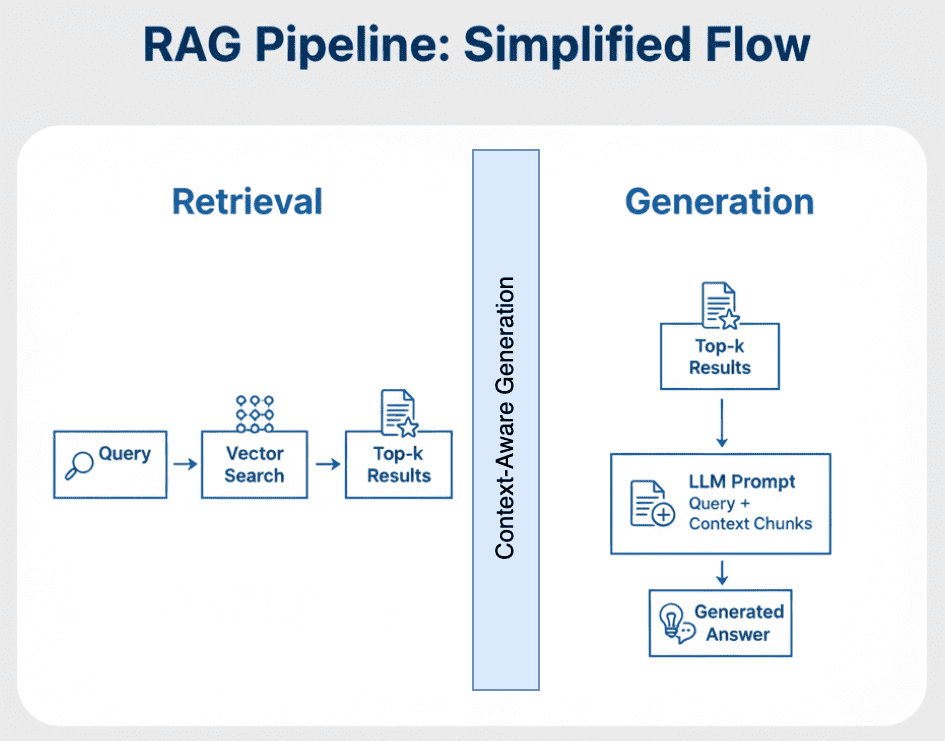
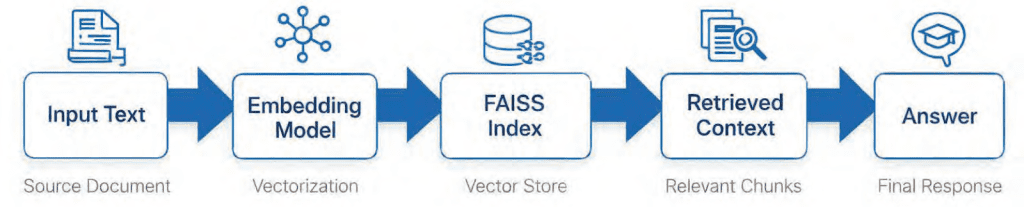
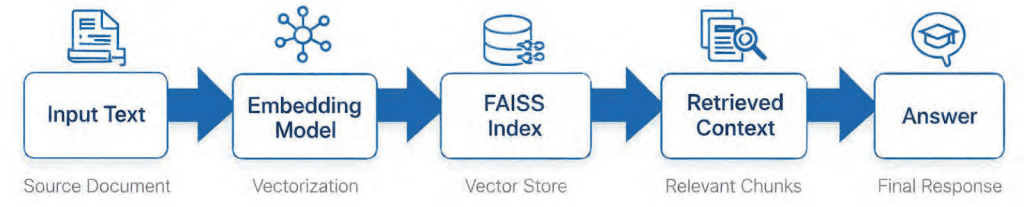
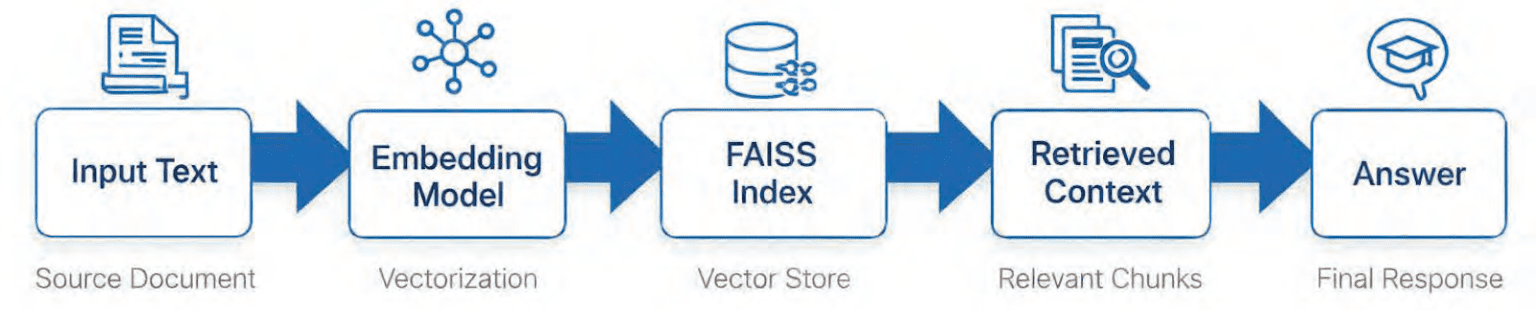
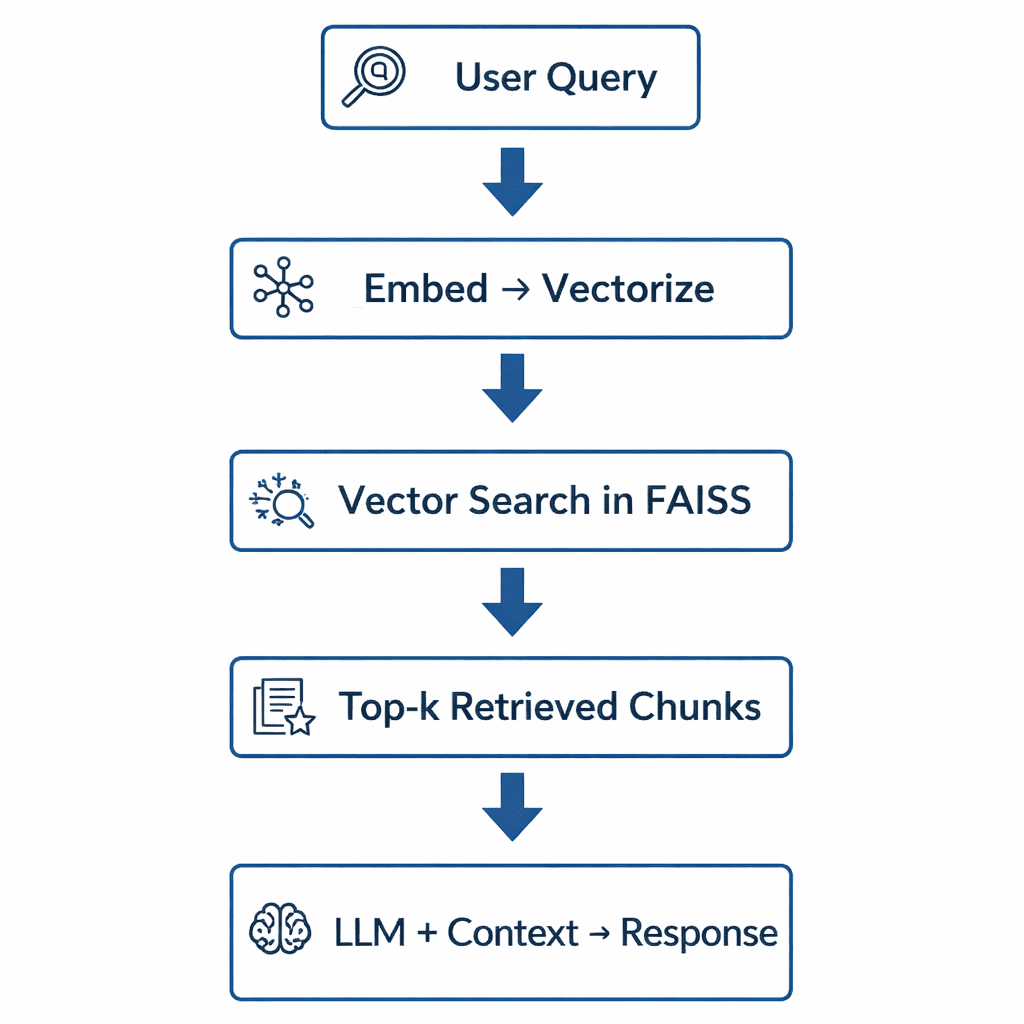
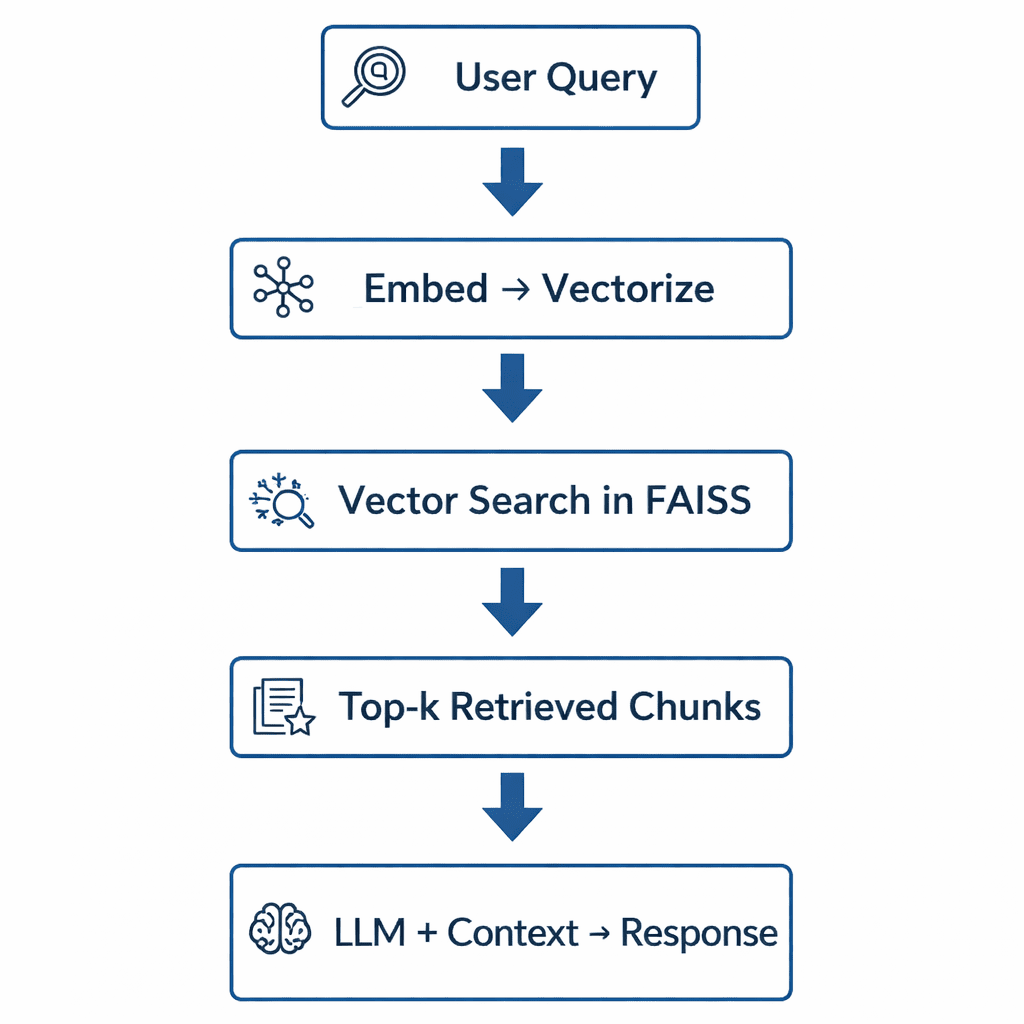
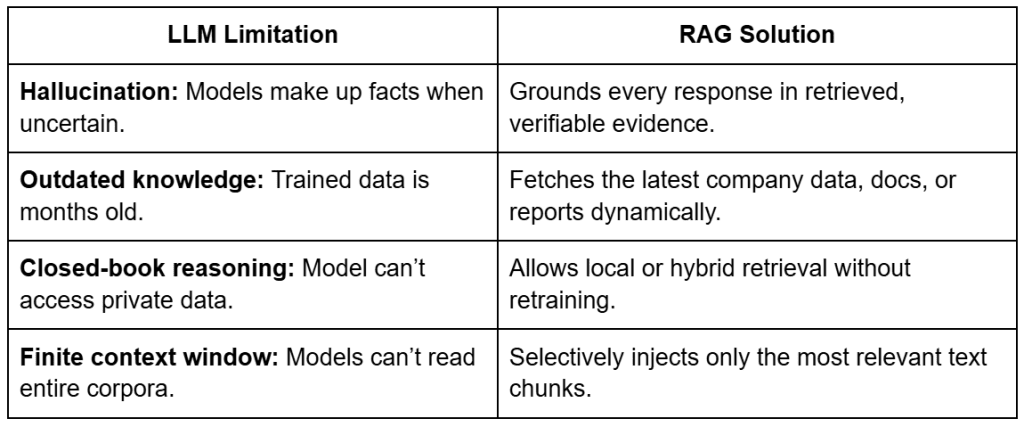
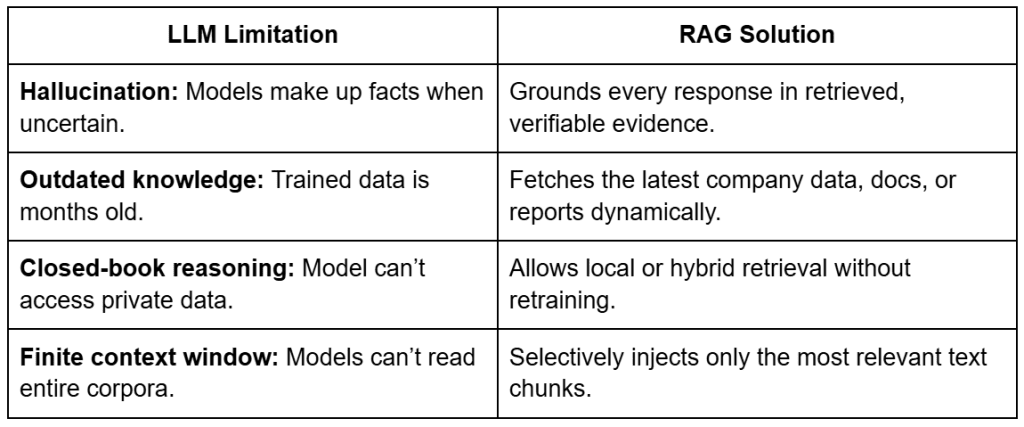
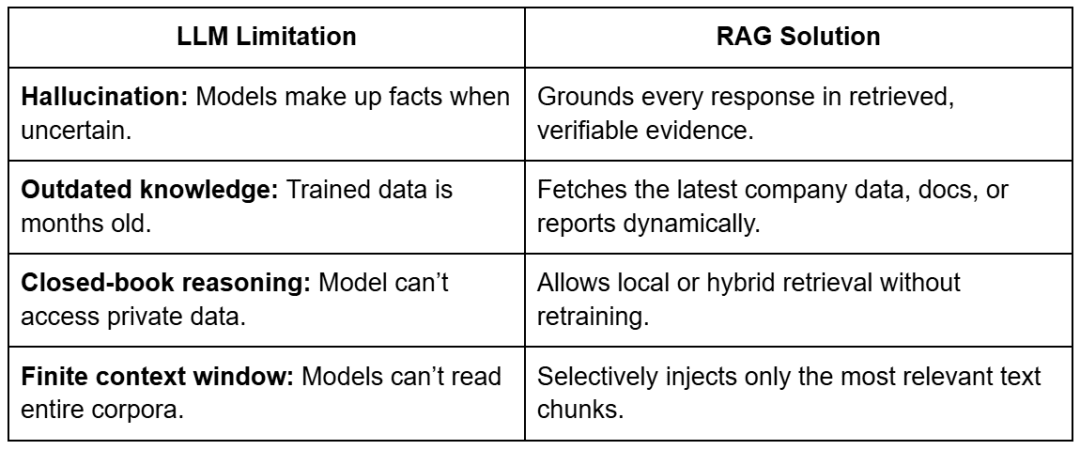
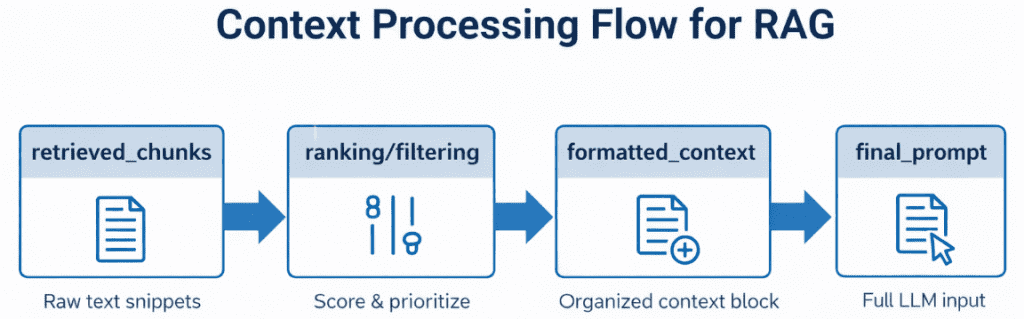
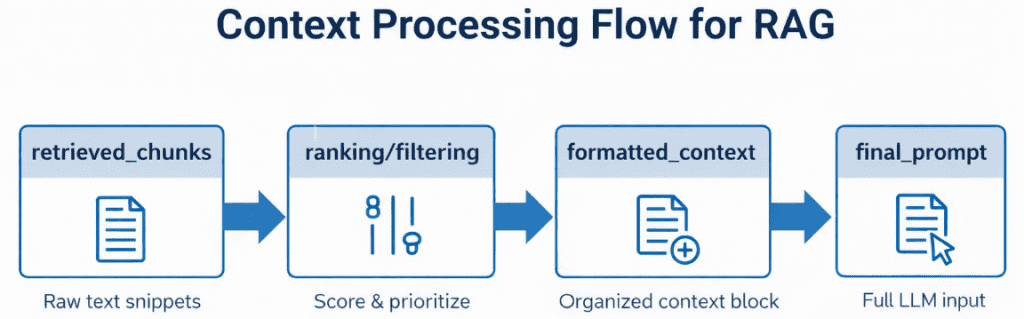
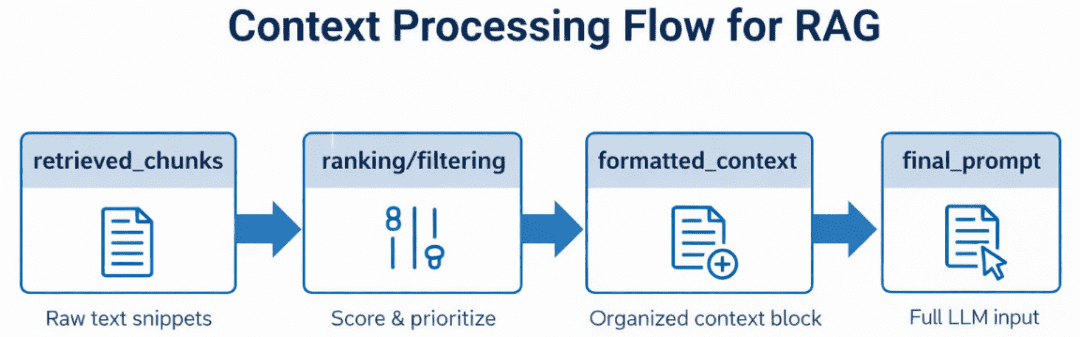
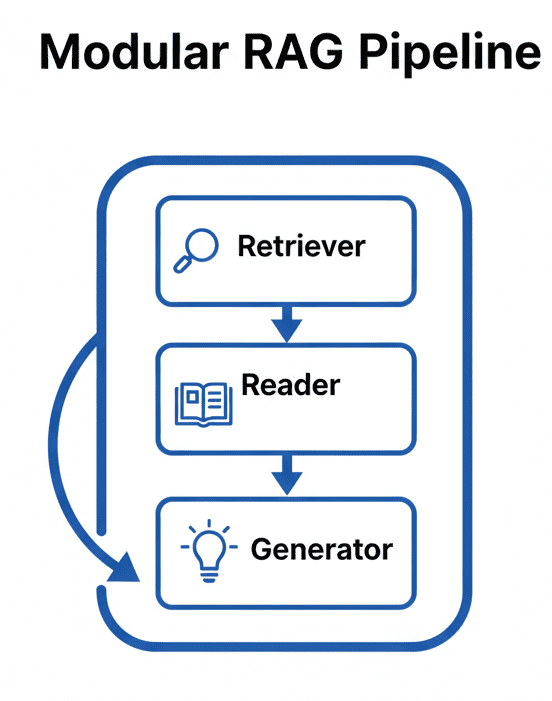
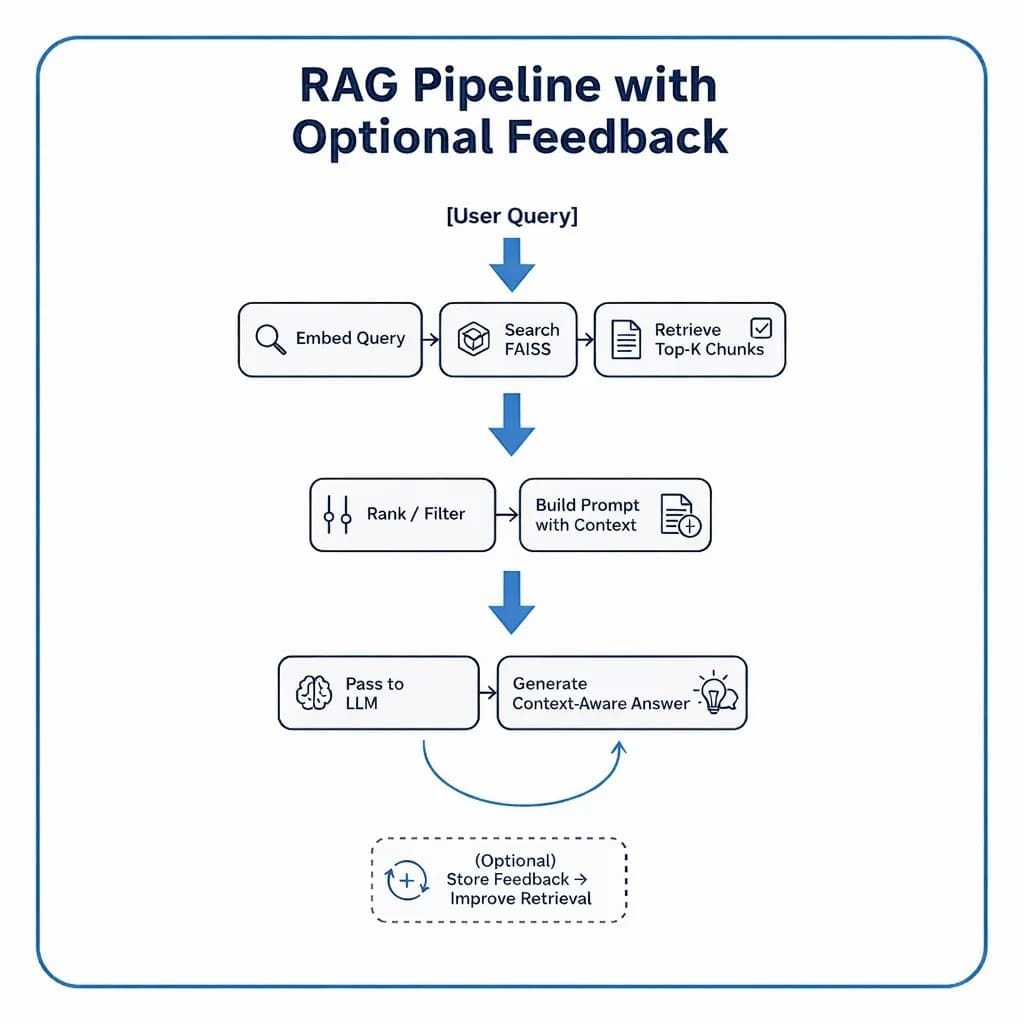
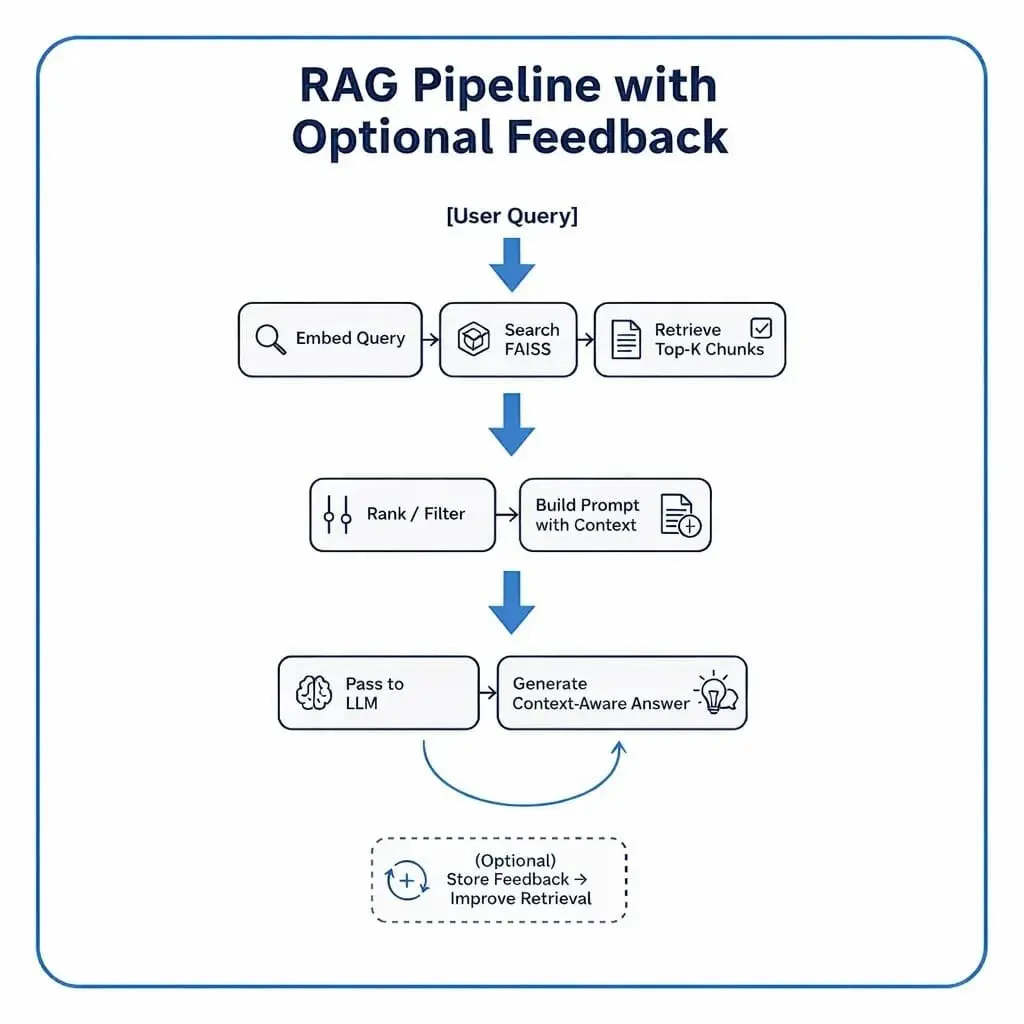
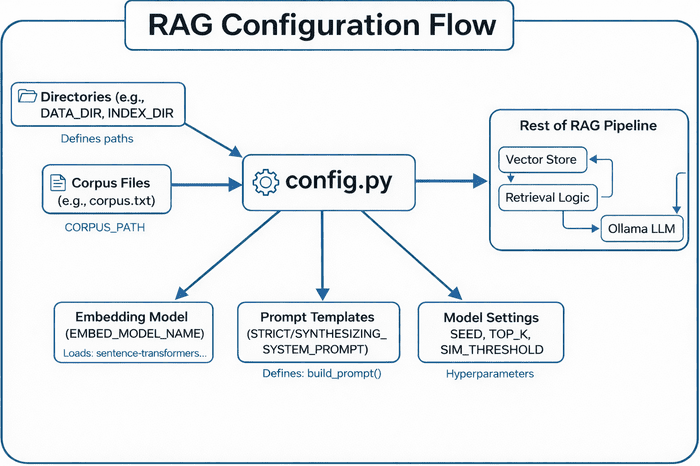
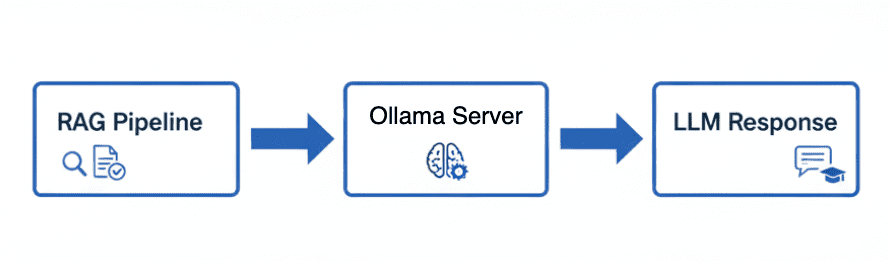
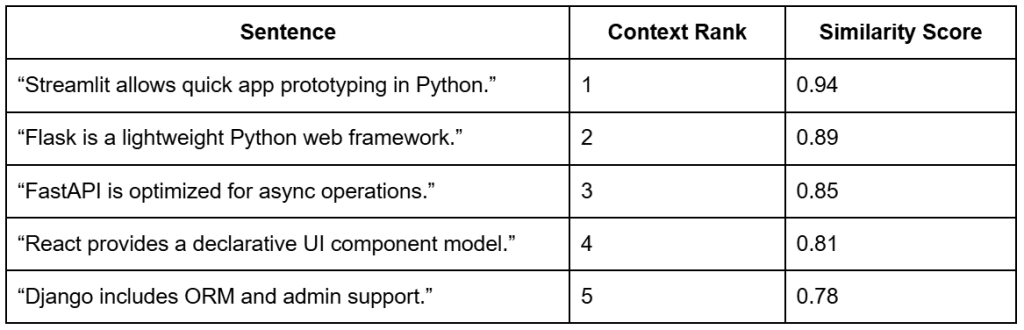
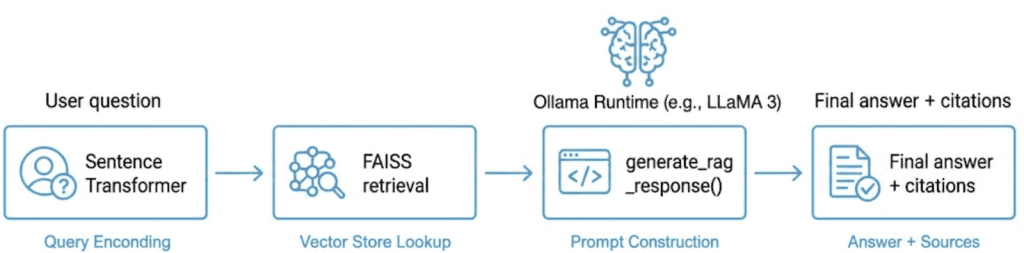
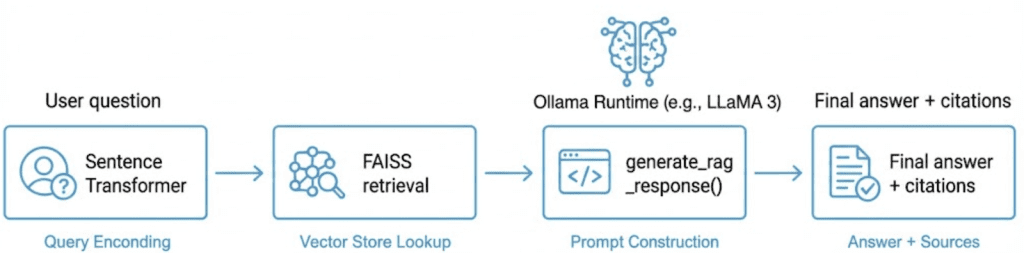
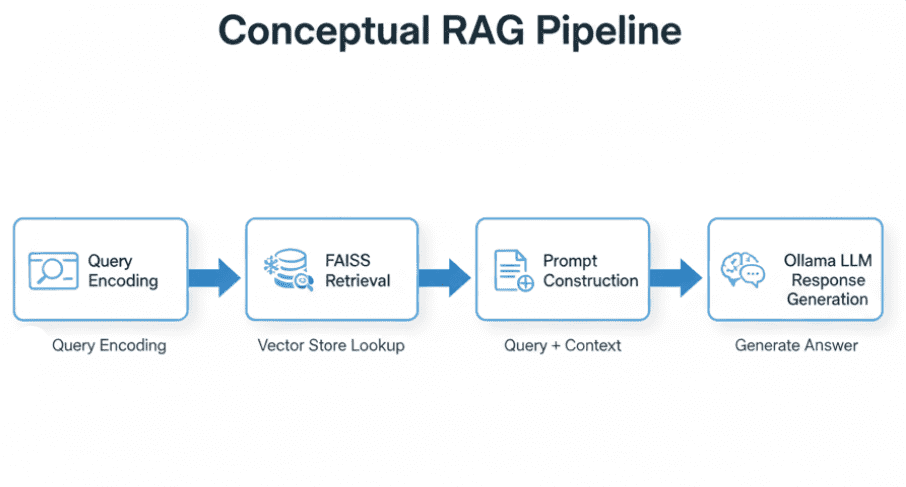
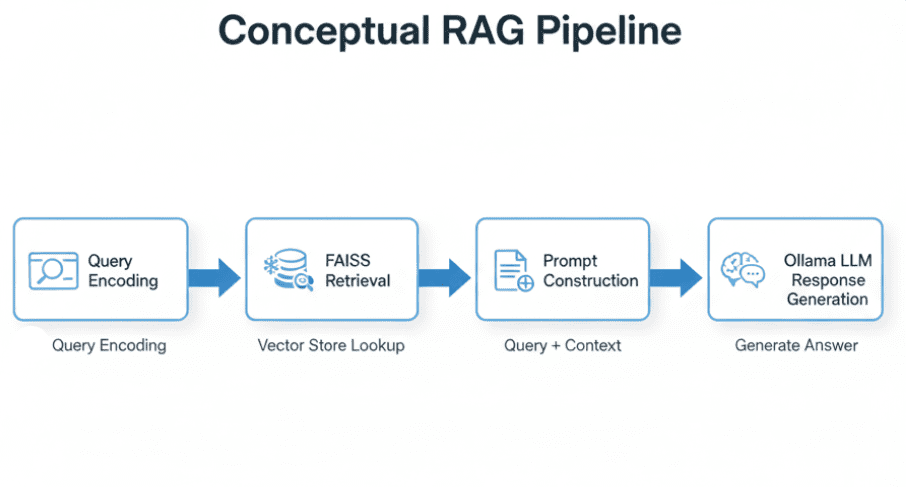
Table of Contents Vector Search Using Ollama for Retrieval-Augmented Generation (RAG) How Vector Search Powers Retrieval-Augmented Generation (RAG) From Search to Context The Flow of Meaning Putting It All Together What Is Retrieval-Augmented Generation (RAG)? The Retrieve-Read-Generate Architecture Explained Why Retrieval-Augmented Generation (RAG) Improves LLM Accuracy The Broader Picture: A Hybrid of Search and Generation Key Takeaway How to Build a RAG Pipeline with FAISS and Ollama (Local LLM) Step 1: Implementing HNSW Vector Search with FAISS for RAG Step 2: Prompt Engineering for Retrieval-Augmented Generation (RAG) Step 3: Generating Grounded Answers with Ollama Local LLM Adding Feedback Loops to Improve Retrieval Accuracy Putting It All Together Configuring Your Development Environment: Setting Up Ollama and FAISS for a Local RAG Pipeline Optional Dependencies Local LLM Setup (Ollama) Implementation Walkthrough Configuration (config.py) Integrating Ollama with FAISS Vector Search for RAG Overview…