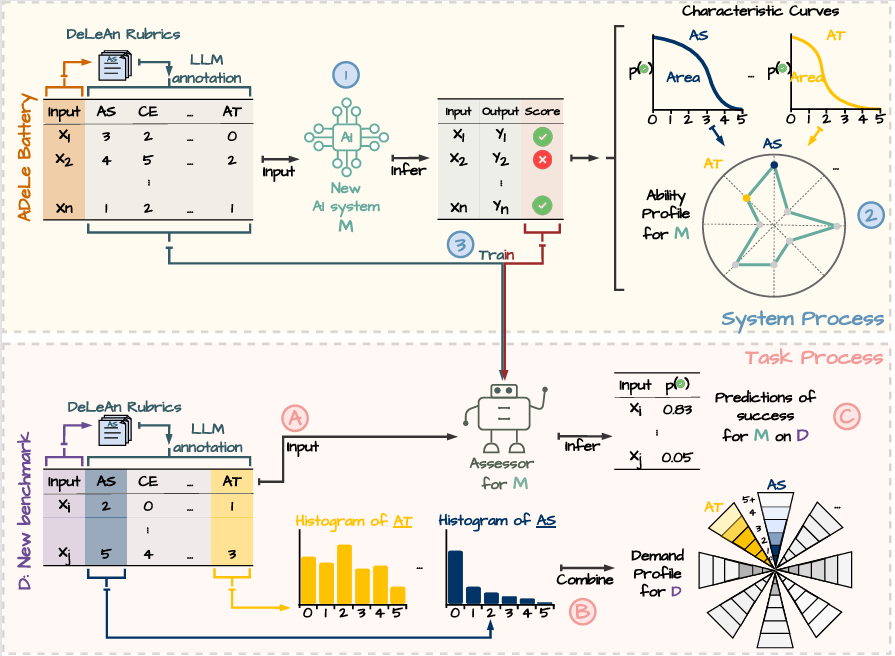
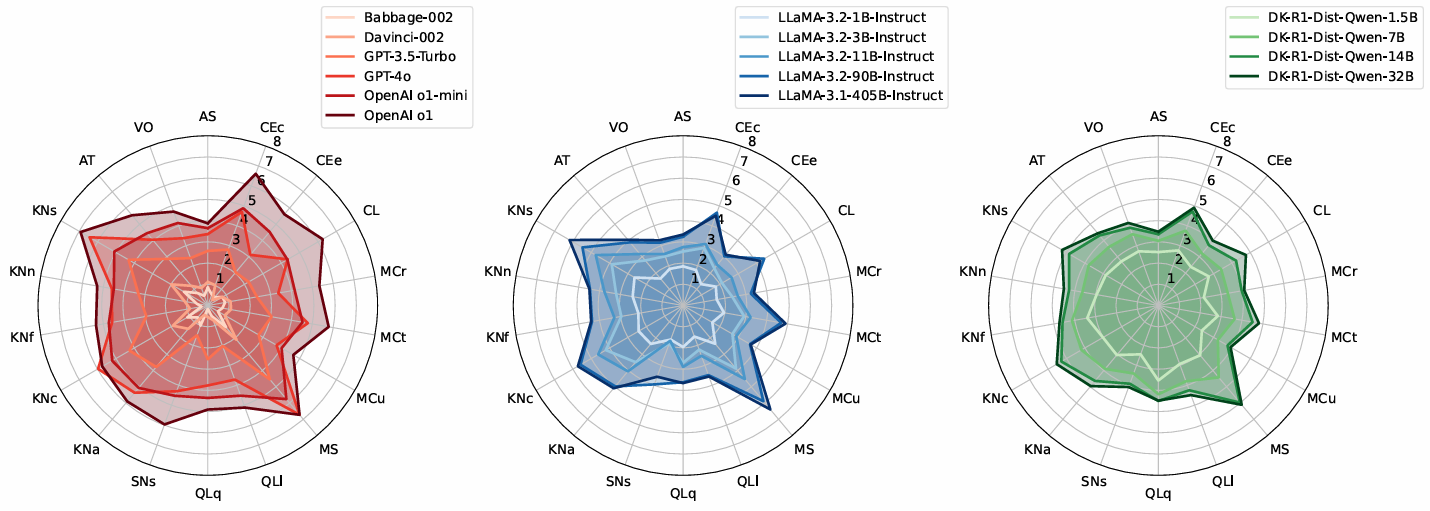
At a glance AI benchmarks report performance on specific tasks but provide limited insight into underlying capabilities; ADeLe evaluates models by scoring both tasks and models across 18 core abilities, enabling direct comparison between task demands and model capabilities. Using these ability scores, the method predicts performance on new tasks with ~88% accuracy, including for models such as GPT-4o and Llama-3.1. It builds ability profiles and identifies where models are likely to succeed or fail, highlighting strengths and limitations across tasks. By linking outcomes to task demands, ADeLe explains differences in performance, showing how it changes as task complexity increases. AI benchmarks report how large language models (LLMs) perform on specific tasks but provide little insight into their underlying capabilities that drive their performance. They do not explain failures or reliably predict outcomes on new tasks.…