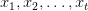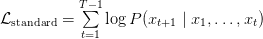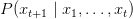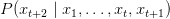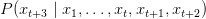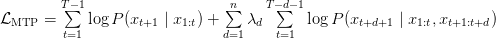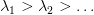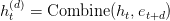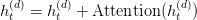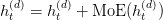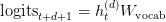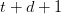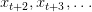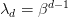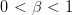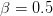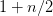Table of Contents Autoregressive Model Limits and Multi-Token Prediction in DeepSeek-V3 Why Next-Token Prediction Limits DeepSeek-V3 Multi-Token Prediction in DeepSeek-V3: Predicting Multiple Tokens Ahead DeepSeek-V3 Architecture: Multi-Token Prediction Heads Explained Gradient Insights for Multi-Token Prediction in DeepSeek-V3 DeepSeek-V3 Training vs. Inference: How MTP Changes Both Multi-Token Prediction Loss Weighting and Decay for DeepSeek-V3 Step-by-Step Implementation of Multi-Token Prediction Heads in DeepSeek-V3 Integrating Multi-Token Prediction with DeepSeek-V3’s Core Transformer Theoretical Foundations: MTP, Curriculum Learning, and Auxiliary Tasks Multi-Token Prediction Benefits: Coherence, Planning, and Faster Convergence Summary Citation Information In the first three parts of this series, we built the foundation of DeepSeek-V3 by implementing its configuration and Rotary Position al Embeddings (RoPE) , exploring the efficiency gains of Multi -H ead Latent Attention (MLA) , and scaling capacity…