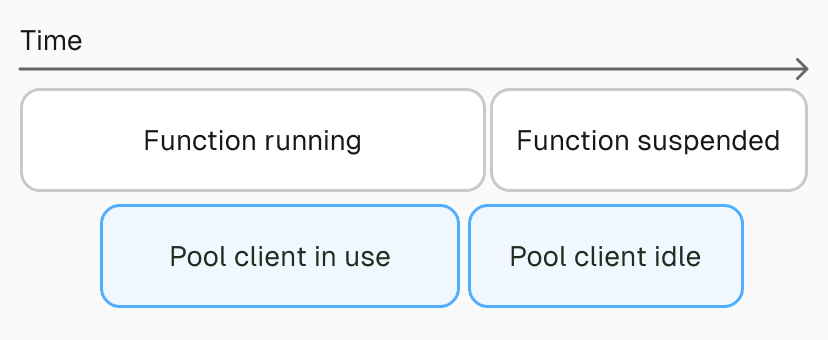
There is a long-standing myth that serverless compute inherently requires more connections to traditional databases. The real issue is not the number of connections needed during normal operation, but that some serverless platforms can leak connections when functions are suspended. In this post, we show why this belief is incorrect, explain the actual cause of the problem, and provide a straightforward, simple-to-use solution. Link to heading You can stop reading now if Your application uses a modern, stateless protocol like HTTP for database connections (for example, DynamoDB, Fauna, or Firestore) You use a connection pooler with such a high maximum connection count that it's effectively unlimited and exhaustion is not a practical concern (for example, AWS RDS Proxy; Google Cloud SQL Auth Proxy and Azure Flexible Server offer similar capabilities, although experiences may vary) For everybody else: Link to heading The ground truth If your application uses a database connection pool (e.g., Postgres, MySQL,…