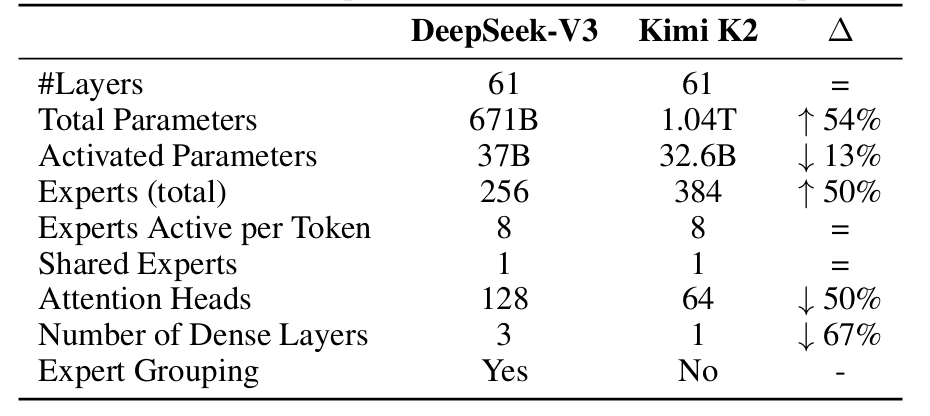
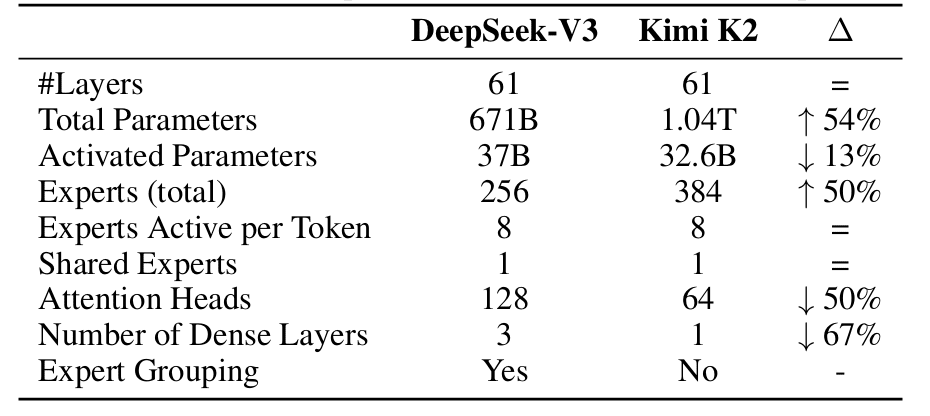
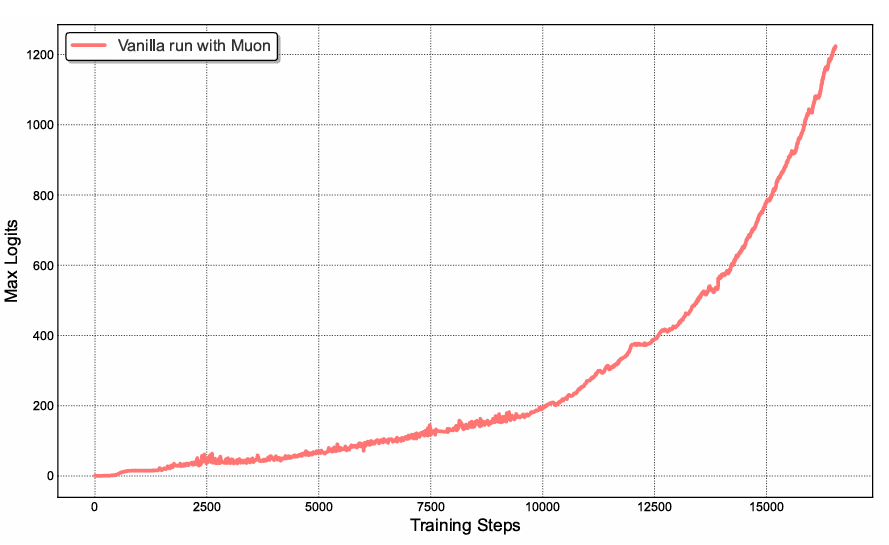
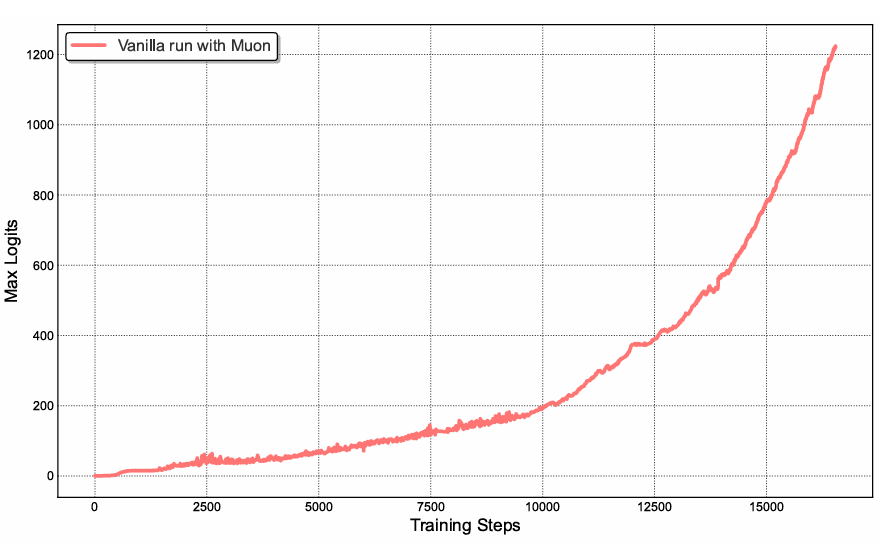
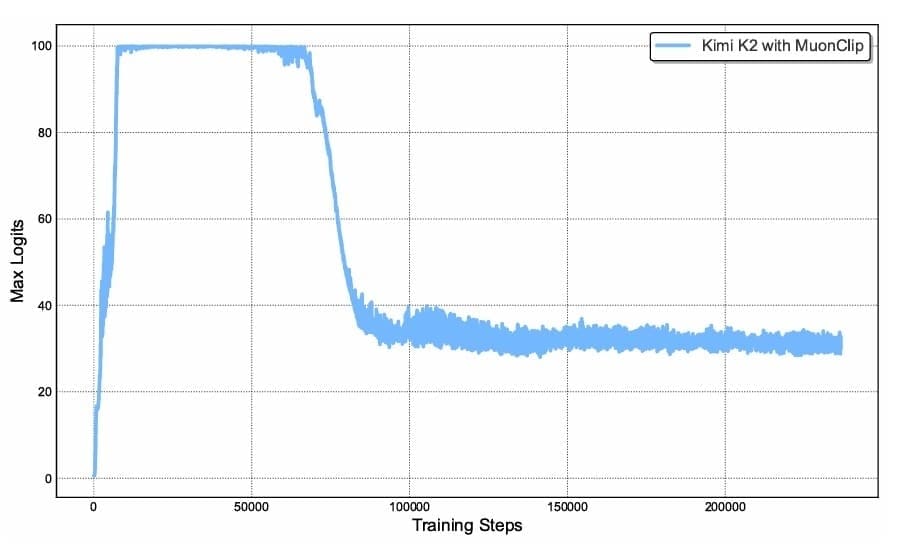
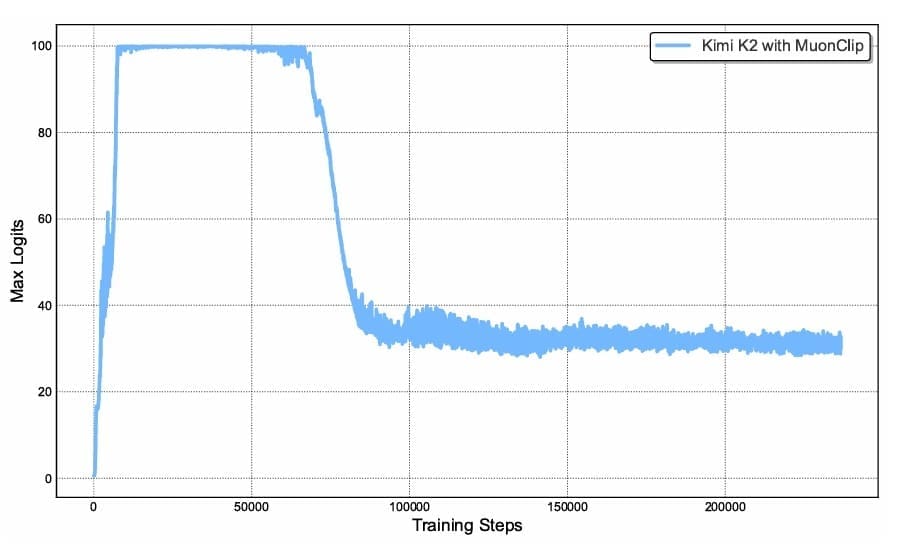
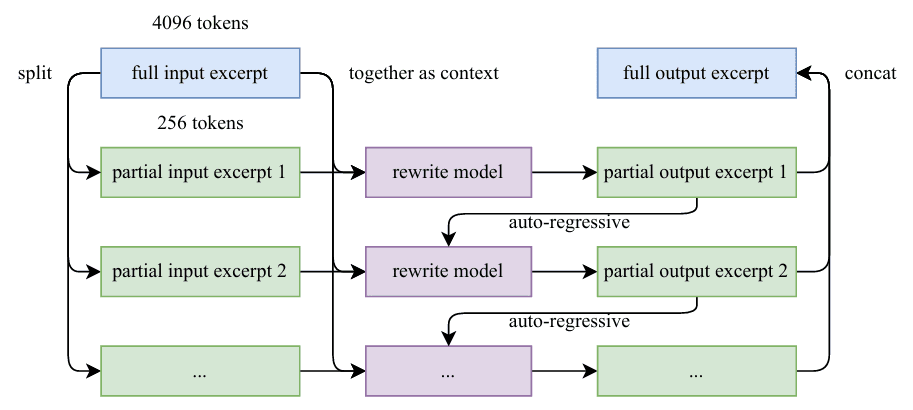
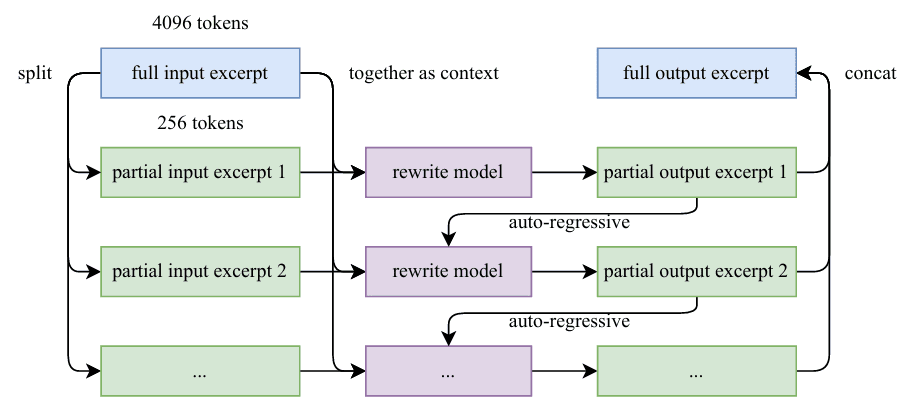
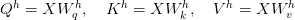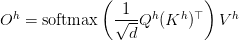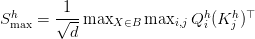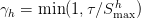Table of Contents Building and Training a Kimi-K2 Model Using DeepSeek-V3 Components Kimi-K2 vs DeepSeek-V3: Key Architecture Differences in LLM Design Mixture of Experts Scaling in Kimi-K2: Model Size, Sparsity, and Efficiency Attention Head Optimization in Kimi-K2 for Efficient Long-Context LLMs MuonClip Optimizer: Stabilizing Large-Scale LLM Training in Kimi-K2 Token Efficiency in LLM Training: Why It Matters for Kimi-K2 Attention Logit Explosion in LLMs: Training Instability and Challenges QK-Clip: Preventing Attention Logit Explosion in Kimi-K2 Training Training Data Optimization for Kimi-K2: Improving Token Utility in LLMs Token Utility in LLM Training: Maximizing Learning per Token Knowledge Data Rephrasing for LLMs: Improving Training Data Quality Kimi-K2 Implementation: Training an Open-Source LLM with DeepSeek-V3 Multi-Head Latent Attention (MLA) with Max Logit Tracking in Kimi-K2 Implementing the MuonClip Optimizer for Stable LLM Training Complete Kimi-K2 Training Pipeline: Setup, Config, and…