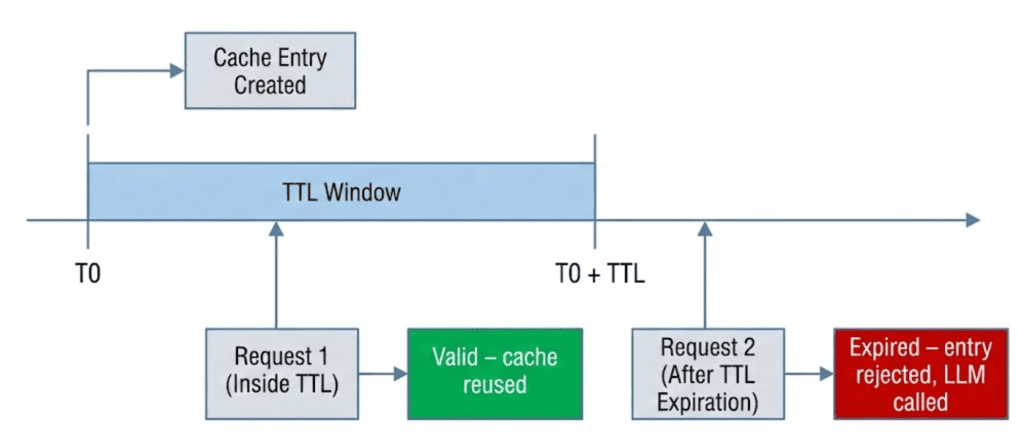
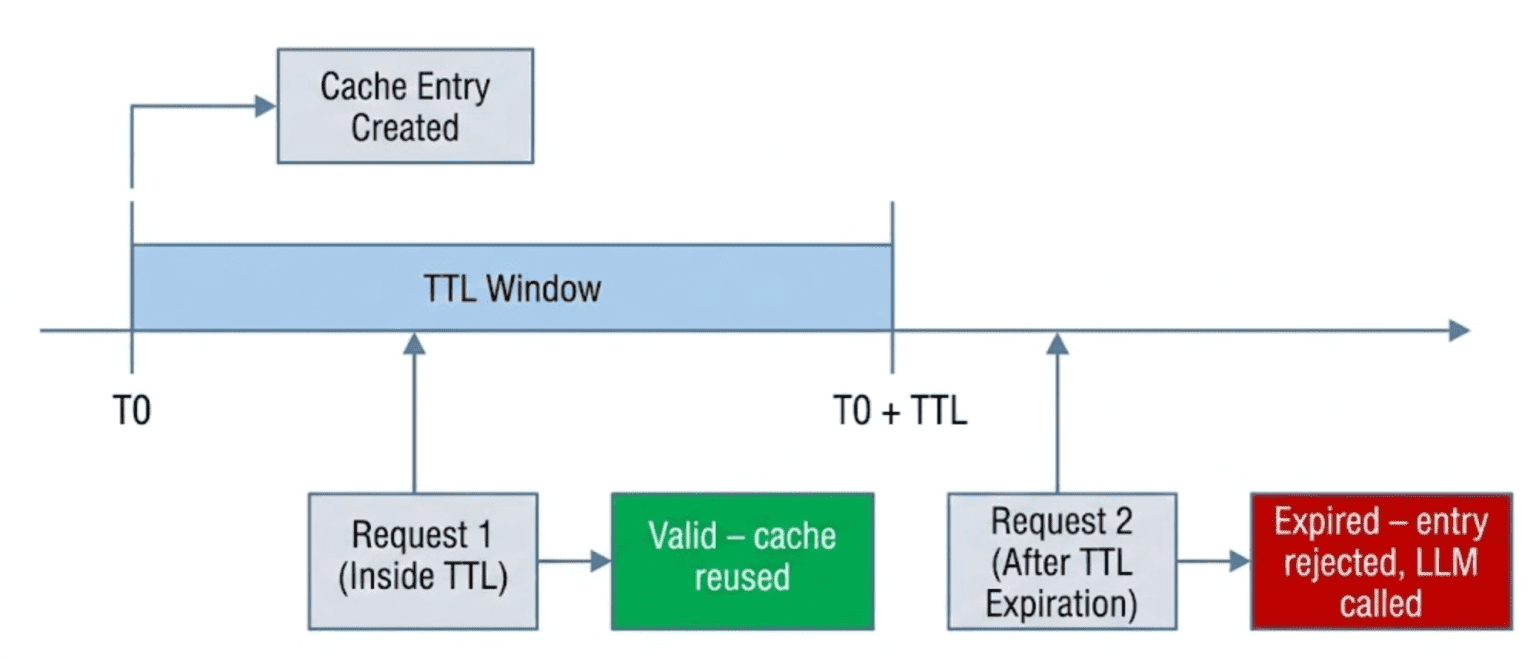
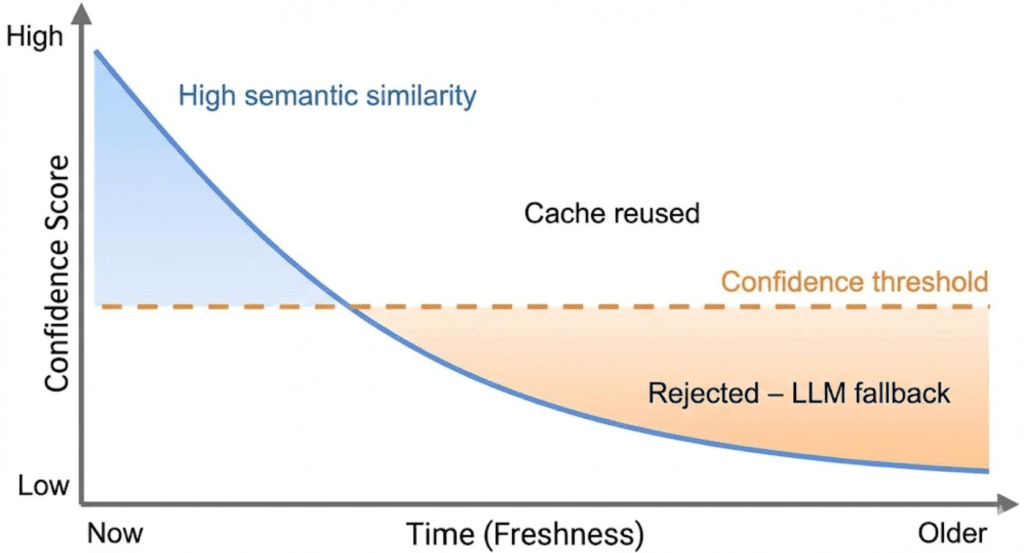
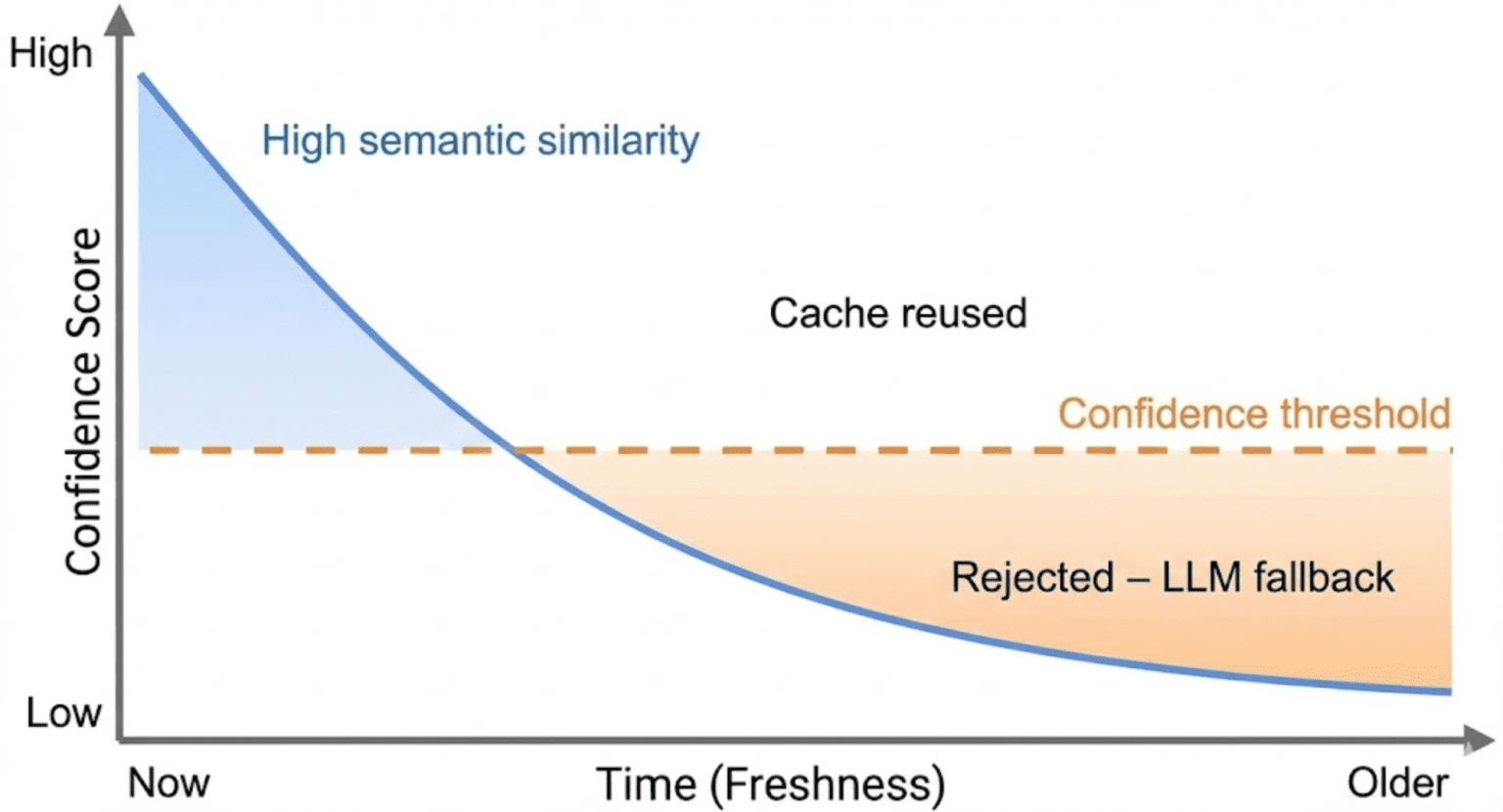
Table of Contents Semantic Caching for LLMs: TTLs, Confidence, and Cache Safety Why Semantic Caching for LLMs Requires Production Hardening Cache TTL in Semantic Caching: Preventing Stale LLM Responses MLOps Project Structure for Semantic Caching with FastAPI and Redis How to Implement Cache TTL Validation in Python and Redis Confidence Scoring in Semantic Caching: Beyond Similarity for LLMs Implementing Confidence Scoring for LLM Cache Optimization (Code Walkthrough) Query Normalization and Deduplication for Efficient Semantic Caching Preventing Cache Poisoning in Semantic Caching for LLM Systems End-to-End Semantic Cache Hardening: TTL, Confidence, and Safety Demos Semantic Caching Limitations: Trade-Offs in LLM Optimization Systems Summary In this lesson, you will learn how to harden a semantic cache for LLMs, one of the most important LLMOps patterns for reducing redundant inference costs, and move from a working semantic caching prototype to a system that can survive real-world usage with TTL…