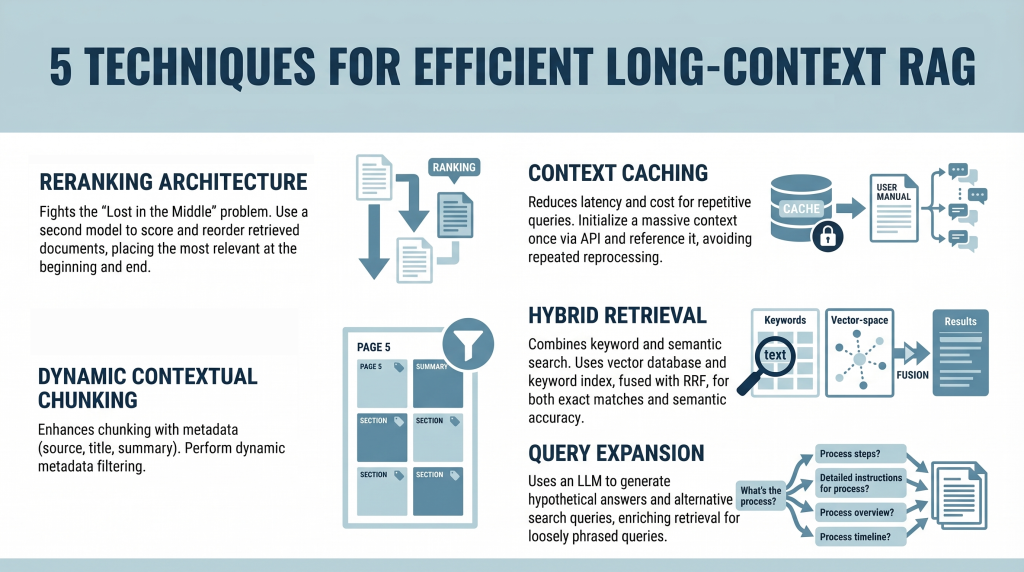
In this article, you will learn how to build efficient long-context retrieval-augmented generation (RAG) systems using modern techniques that address attention limitations and cost challenges. Topics we will cover include: How reranking mitigates the “Lost in the Middle” problem. How context caching reduces latency and computational cost. How hybrid retrieval, metadata filtering, and query expansion improve relevance. Introduction Retrieval-augmented generation (RAG) is undergoing a major shift. For years, the RAG mantra was simple: “ Break your documents into smaller pieces, embed them, and retrieve the most relevant pieces .” This was necessary because large language models (LLMs) had context windows that were expensive and limited, typically ranging from 4,000 to 32,000 tokens. Now, models like Gemini Pro and Claude Opus have broken these limits, offering context windows of 1 million tokens or more. In theory, you could now paste an entire collection of novels into a prompt.…