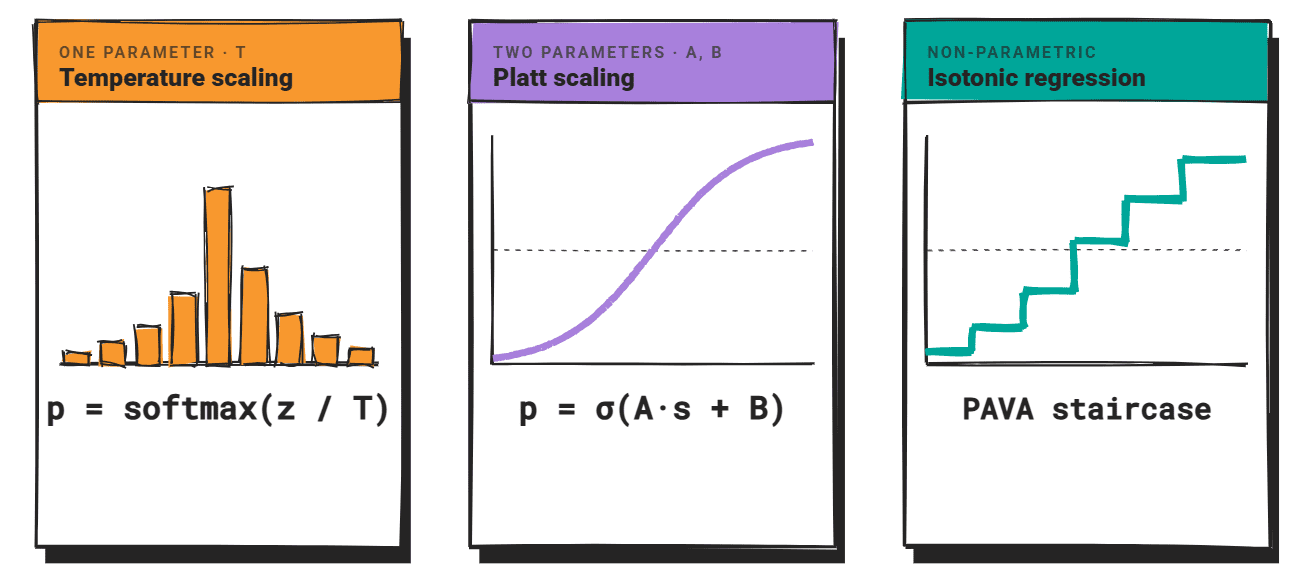
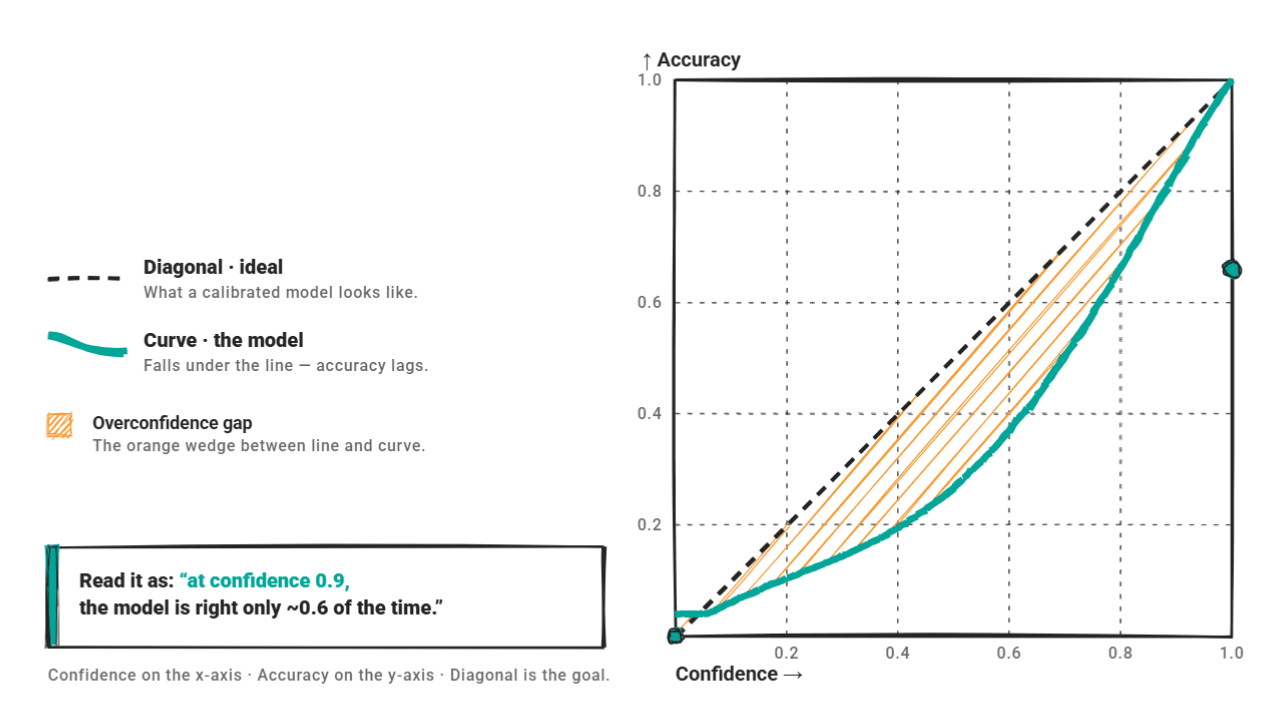
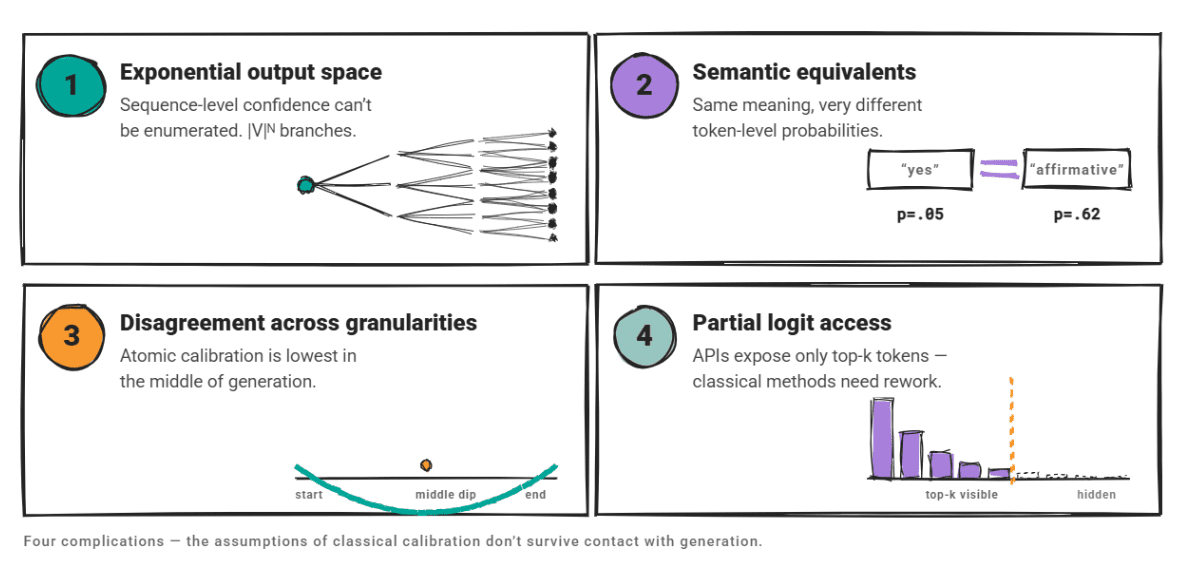
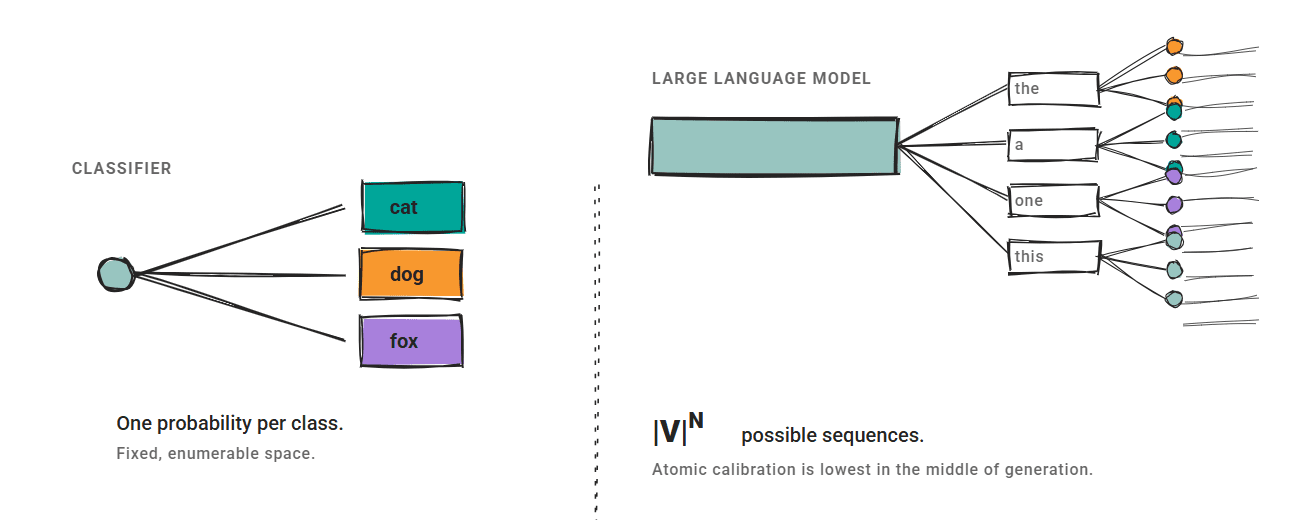
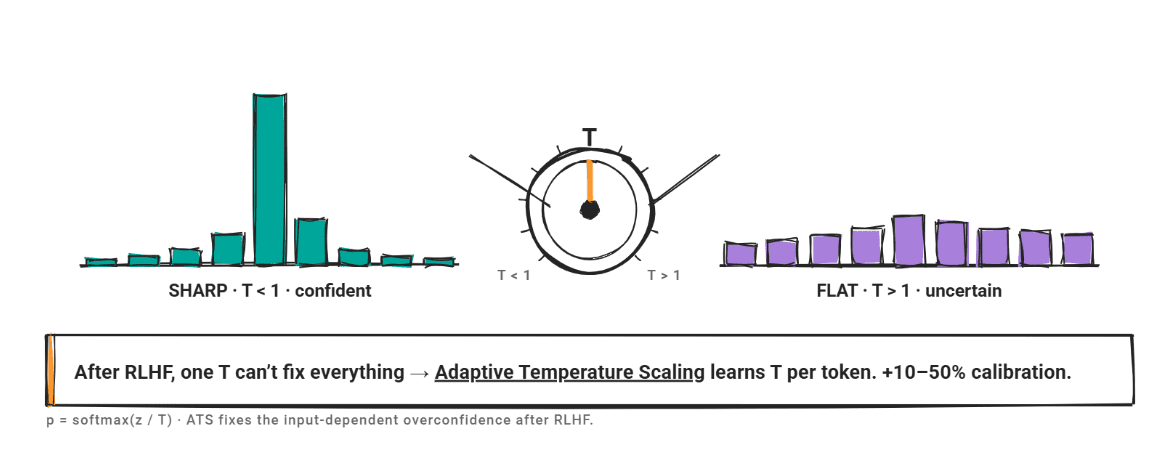
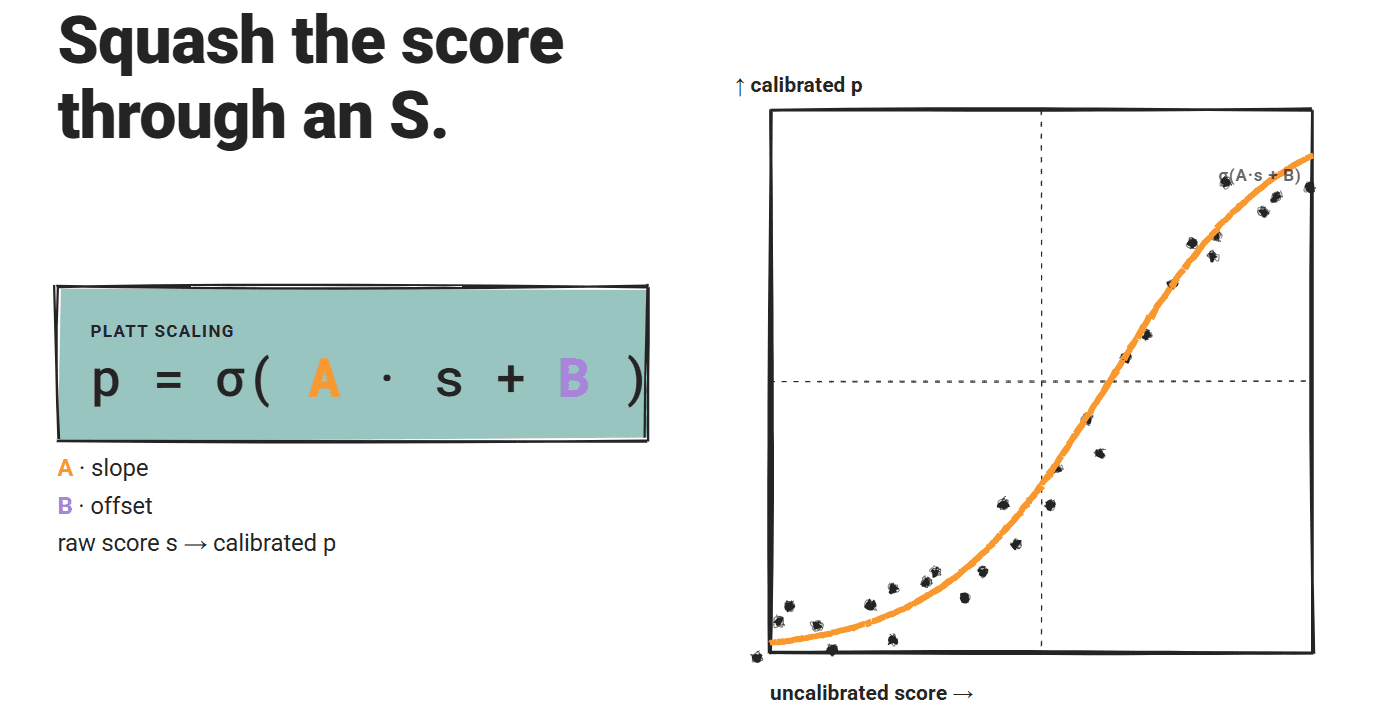
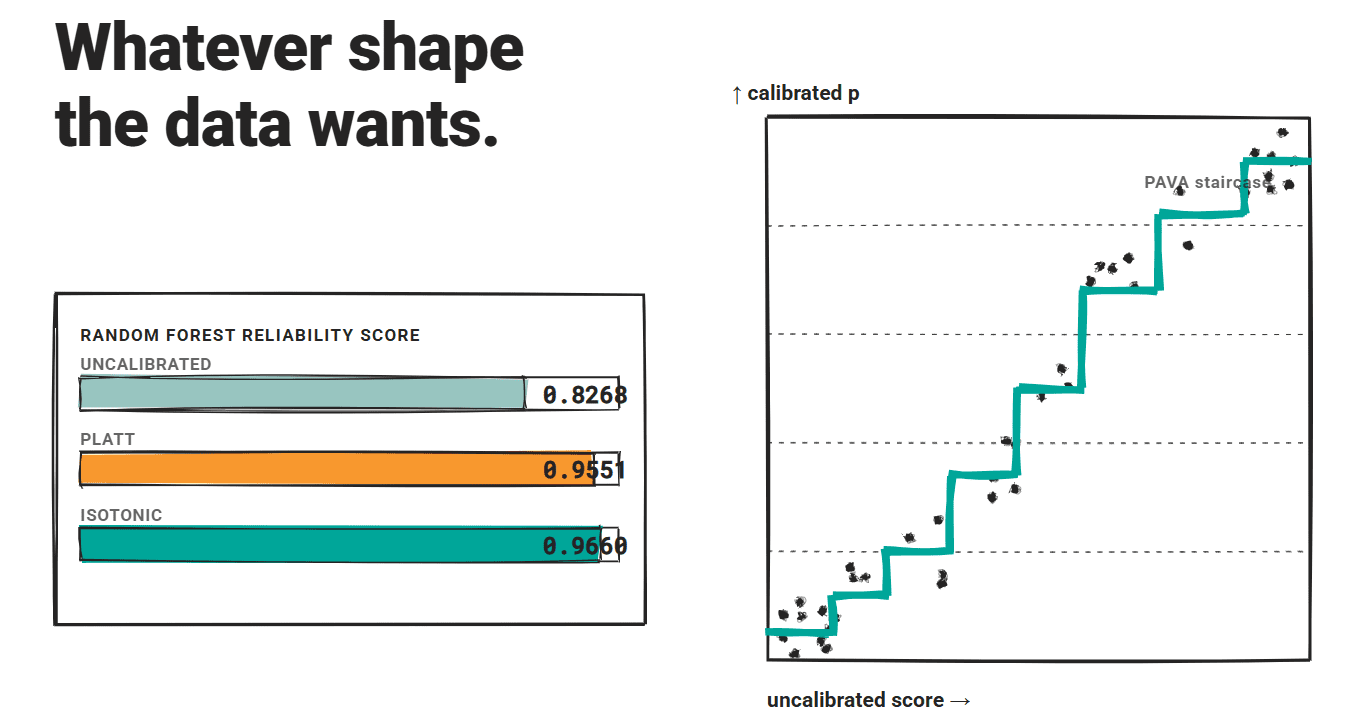
# Introduction A model that says it is 90% confident should be right 90% of the time. When that relationship breaks down, you get a miscalibration problem. The model's scores stop telling you anything useful about reliability. For large language models (LLMs), miscalibration is widespread. A 2024 NAACL survey found that confidence scores diverge from actual correctness rates across factual QA, code generation, and reasoning tasks. Another study on biomedical models found mean calibration scores ranging from only 23.9% to 46.6% across all tested models. The gap is consistent. The standard solution in classical machine learning is post-hoc recalibration: fit a simple function on a held-out validation set to map raw confidence scores to better-calibrated probabilities. Three methods dominate: temperature scaling , Platt scaling , and isotonic regression . All three were designed for discriminative classifiers , and applying them to LLMs requires care.…