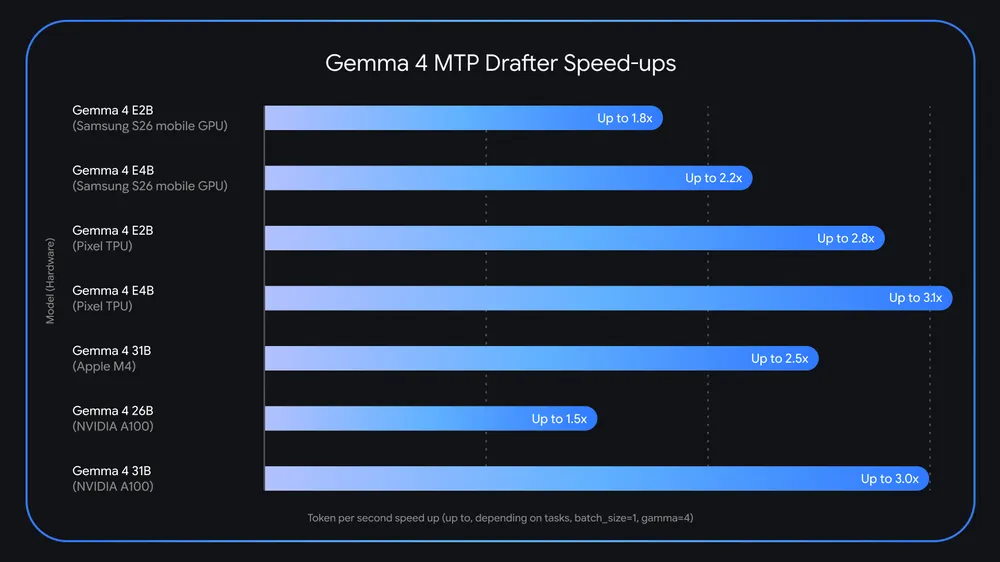
Google launched its Gemma 4 open models this spring, promising a new level of power and performance for local AI. Google’s take on edge AI could be getting even faster already with the release of Multi-Token Prediction (MTP) drafters for Gemma. Google says these experimental models leverage a form of speculative decoding to take a guess at future tokens, which can speed up generation compared to the way models generate tokens on their own. The latest Gemma models are built on the same underlying technology that powers Google’s frontier Gemini AI, but they’re tuned to run locally. Gemini is optimized to run on Google’s custom TPU chips , which operate in enormous clusters with super-fast interconnects and memory. A single high-power AI accelerator can run the largest Gemma 4 model at full precision, and quantizing will let it run on a consumer GPU. Gemma allows users to tinker with AI on their hardware rather than sharing all their data with a cloud AI system from Google or someone else.…