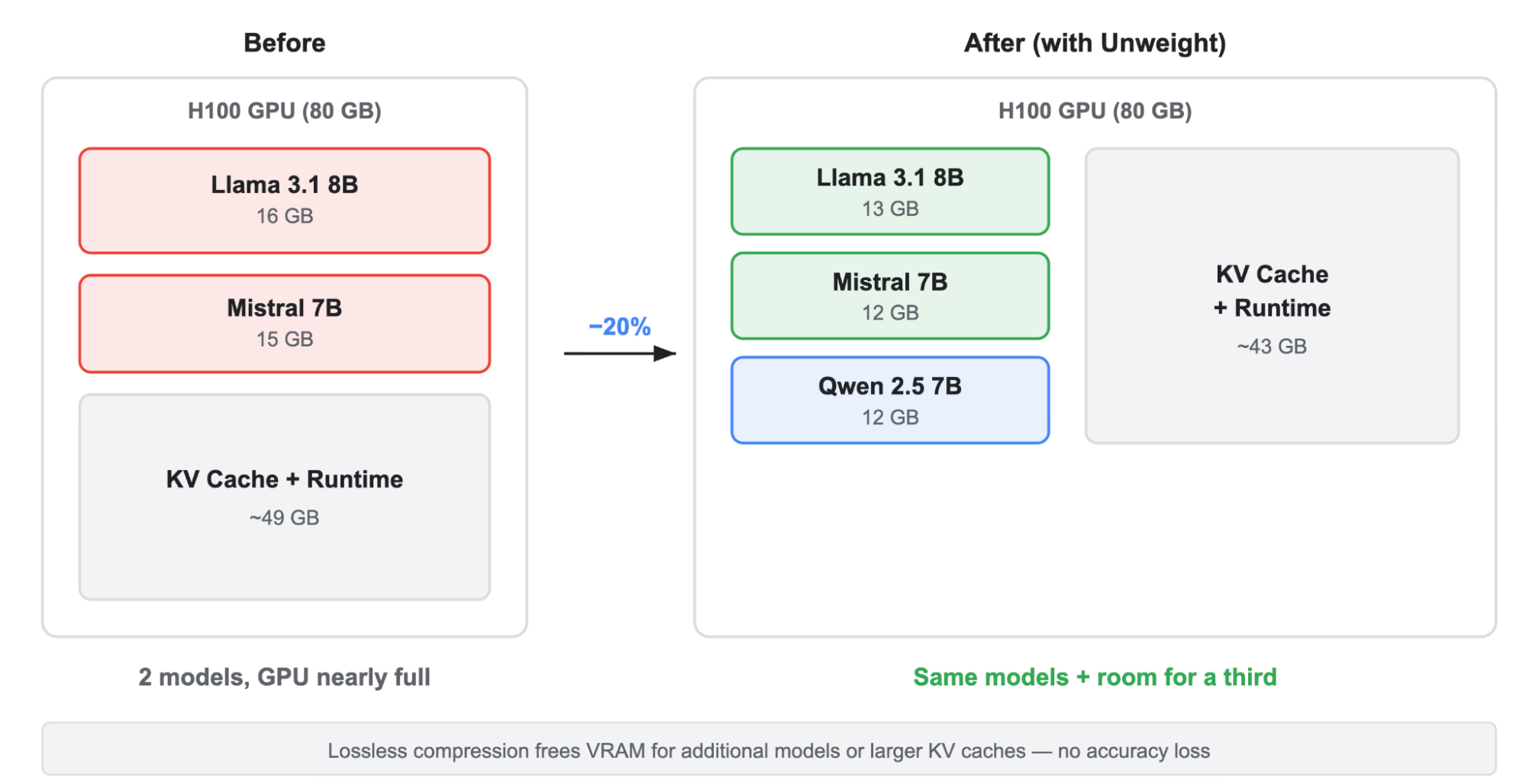
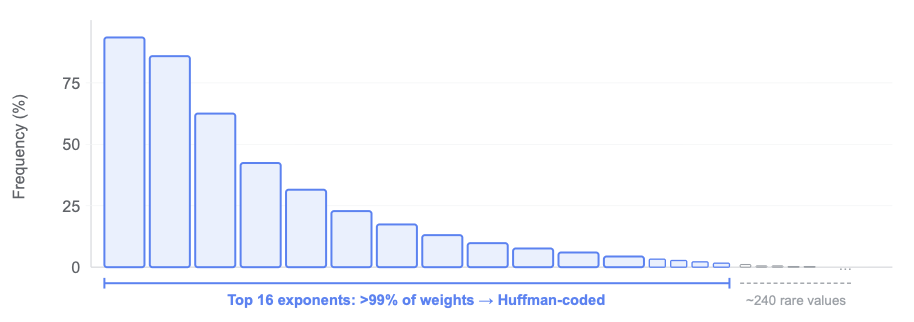
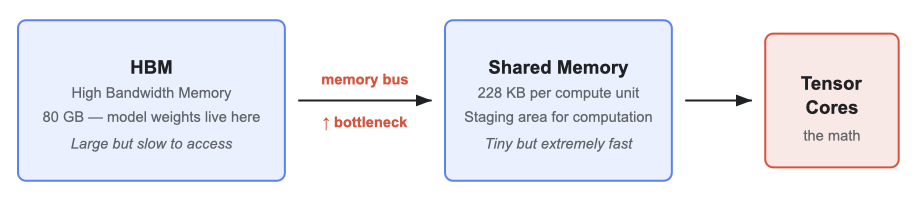
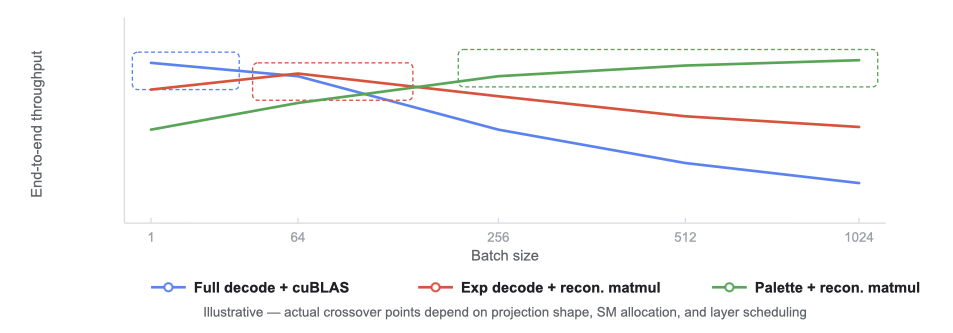
2026-04-17 12 min read Running inference within 50ms of 95% of the world's Internet-connected population means being ruthlessly efficient with GPU memory. Last year we improved memory utilization with Infire , our Rust-based inference engine, and eliminated cold-starts with Omni , our model scheduling platform. Now we are tackling the next big bottleneck in our inference platform: model weights. Generating a single token from an LLM requires reading every model weight from GPU memory. On the NVIDIA H100 GPUs we use in many of our datacenters, the tensor cores can process data nearly 600 times faster than memory can deliver it, leading to a bottleneck not in compute, but memory bandwidth. Every byte that crosses the memory bus is a byte that could have been avoided if the weights were smaller. To solve this problem, we built Unweight : a lossless compression system that can make model weights up to 15–22% smaller while preserving bit-exact outputs, without relying on any special hardware.…