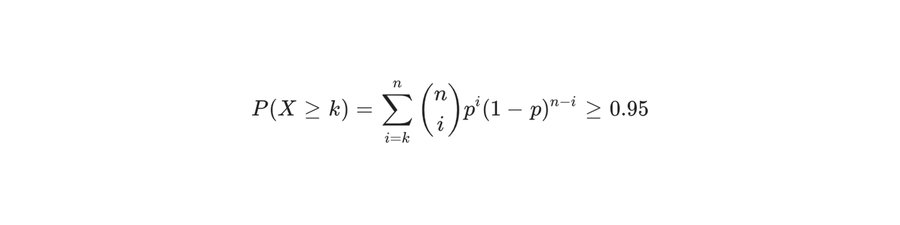Frontier AI models have redefined the unit of compute. At trillion-parameter scale, AI training requires thousands of interconnected components, orchestrated in industrial-scale deployments to operate as a single, massive entity. Likewise, when it comes to reliability, aggregate infrastructure availability is what matters. Yet for almost two decades, instance-level reliability has been the cloud standard. Designed for microservices and horizontally scalable applications, instance-level reliability treats infrastructure as a collection of small independent units. This model is fundamentally inadequate for large-scale AI workloads. We believe reliability must shift from an instance- to a cluster-level model. For over a decade, Google has operated Tensor Processing Unit (TPU) clusters at scale, achieving reliability that meets the architectural requirements of modern AI workloads.…