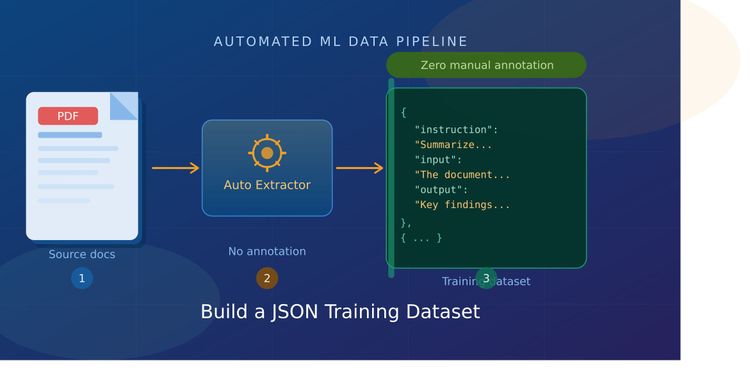
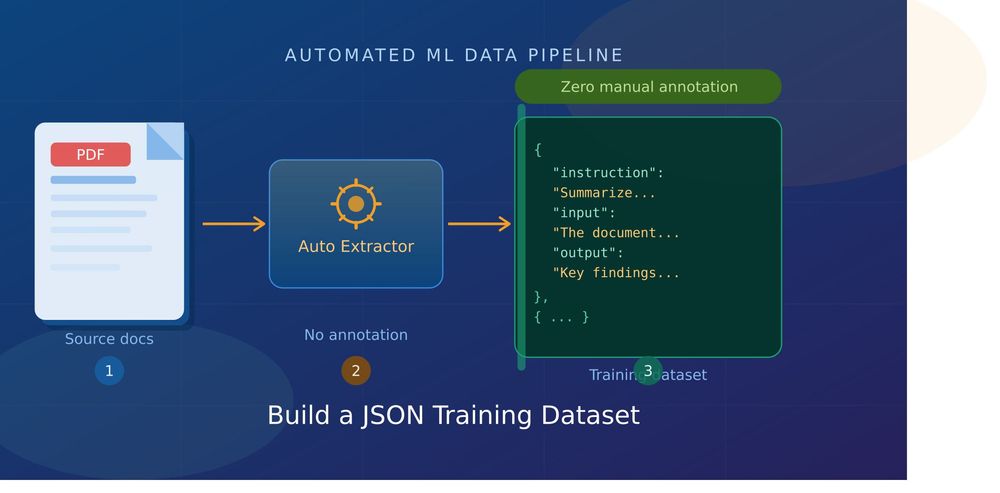
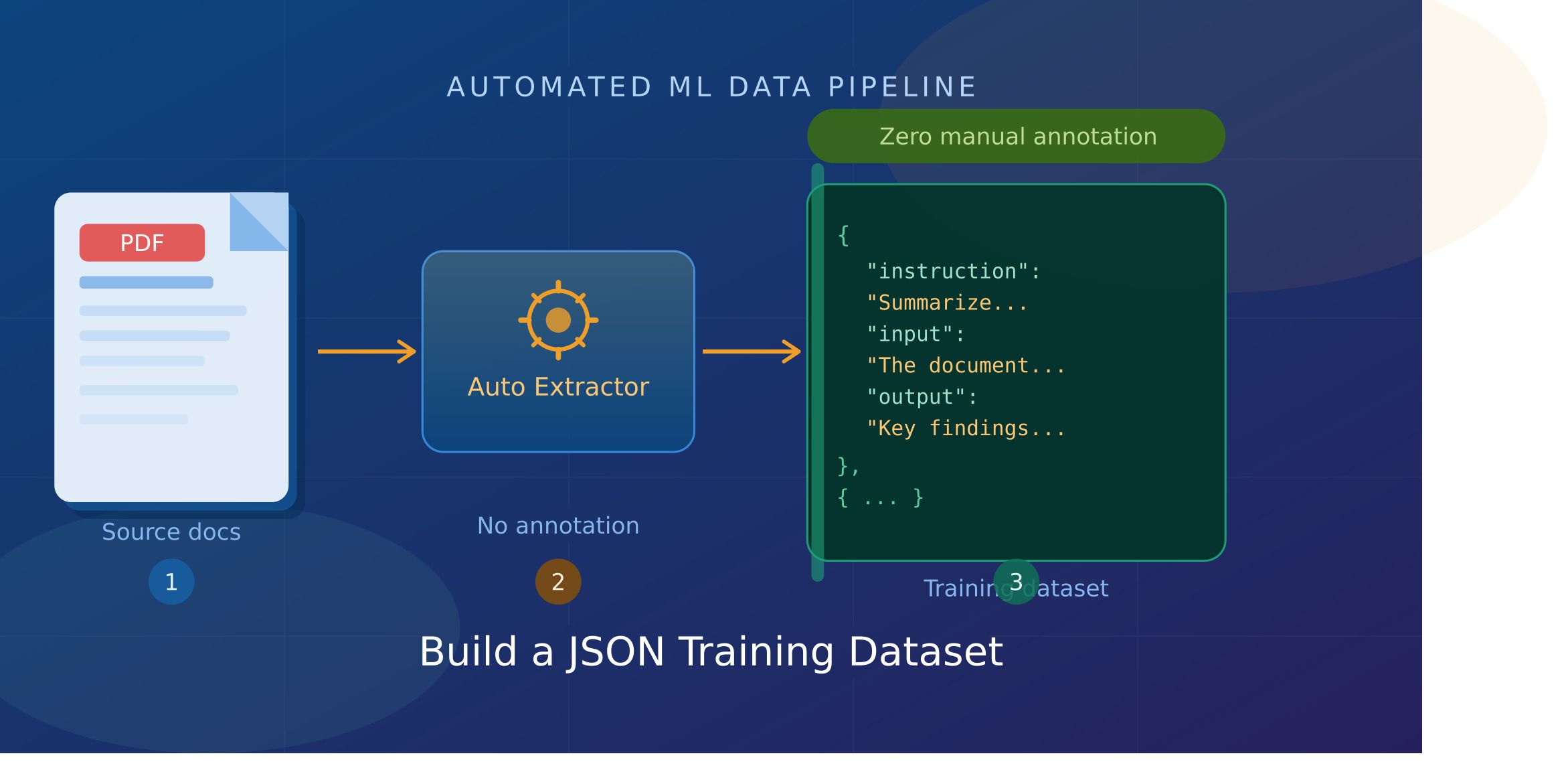
Community Article Community Articles are user-generated content and are not reviewed by SitePoint. Building quality training datasets is one of the most time-consuming parts of any machine learning project. For most teams, that bottleneck isn't compute or model architecture, it's data . More specifically, it's the hours spent manually annotating documents before you can even start training. PDFs are everywhere in the enterprise. Legal contracts, research papers, technical manuals, financial reports, product documentation, they contain exactly the kind of domain-specific knowledge that makes fine-tuned models valuable. The problem is that turning those PDFs into structured, ready-to-train JSON datasets has traditionally required either expensive human annotation or a lot of brittle custom scripting.…