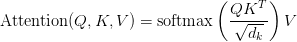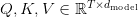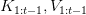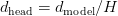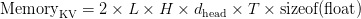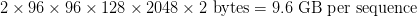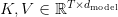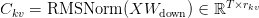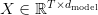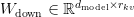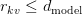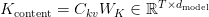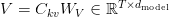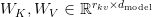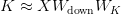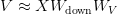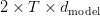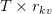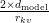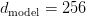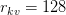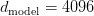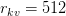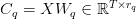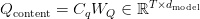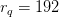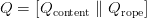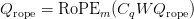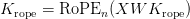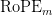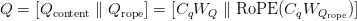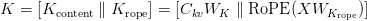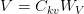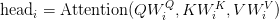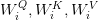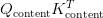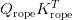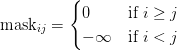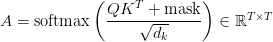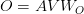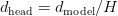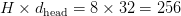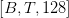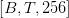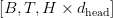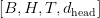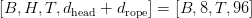Table of Contents Build DeepSeek-V3: Multi-Head Latent Attention (MLA) Architecture The KV Cache Memory Problem in DeepSeek-V3 Multi-Head Latent Attention (MLA): KV Cache Compression with Low-Rank Projections Query Compression and Rotary Positional Embeddings (RoPE) Integration Attention Computation with Multi-Head Latent Attention (MLA) Implementation: Multi-Head Latent Attention (MLA) Multi-Head Latent Attention and KV Cache Optimization Summary Citation Information In the first part of this series, we laid the foundation by exploring the theoretical underpinnings of DeepSeek-V3 and implementing key configuration elements such as Rotary Position al Embeddings (RoPE) . That tutorial established how DeepSeek-V3 manages long-range dependencies and sets up its architecture for efficient scaling. By grounding theory in working code, we ensured that readers not only understood the concepts but also saw how they translate into practical implementation.…