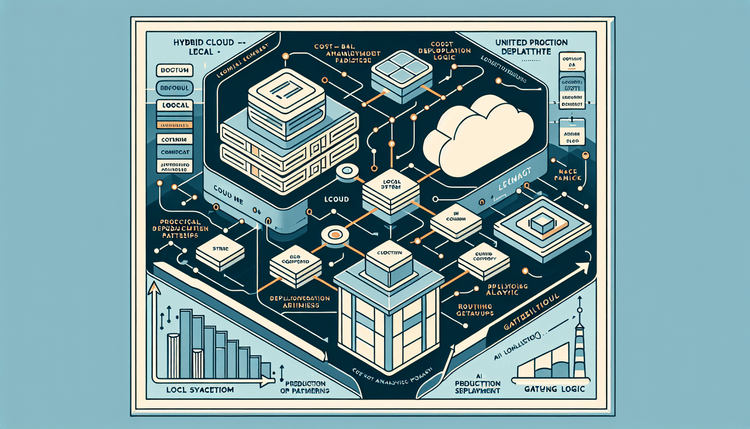
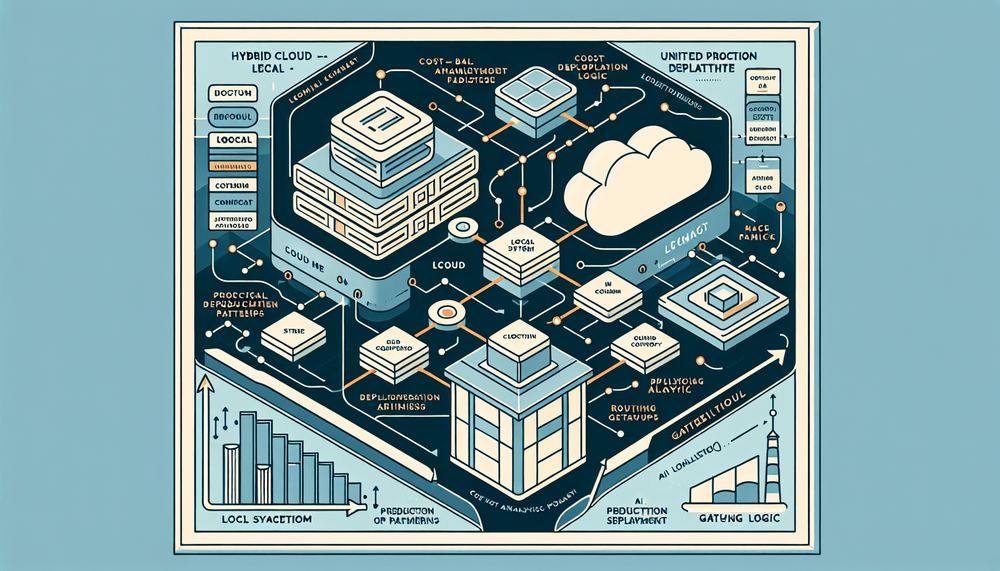
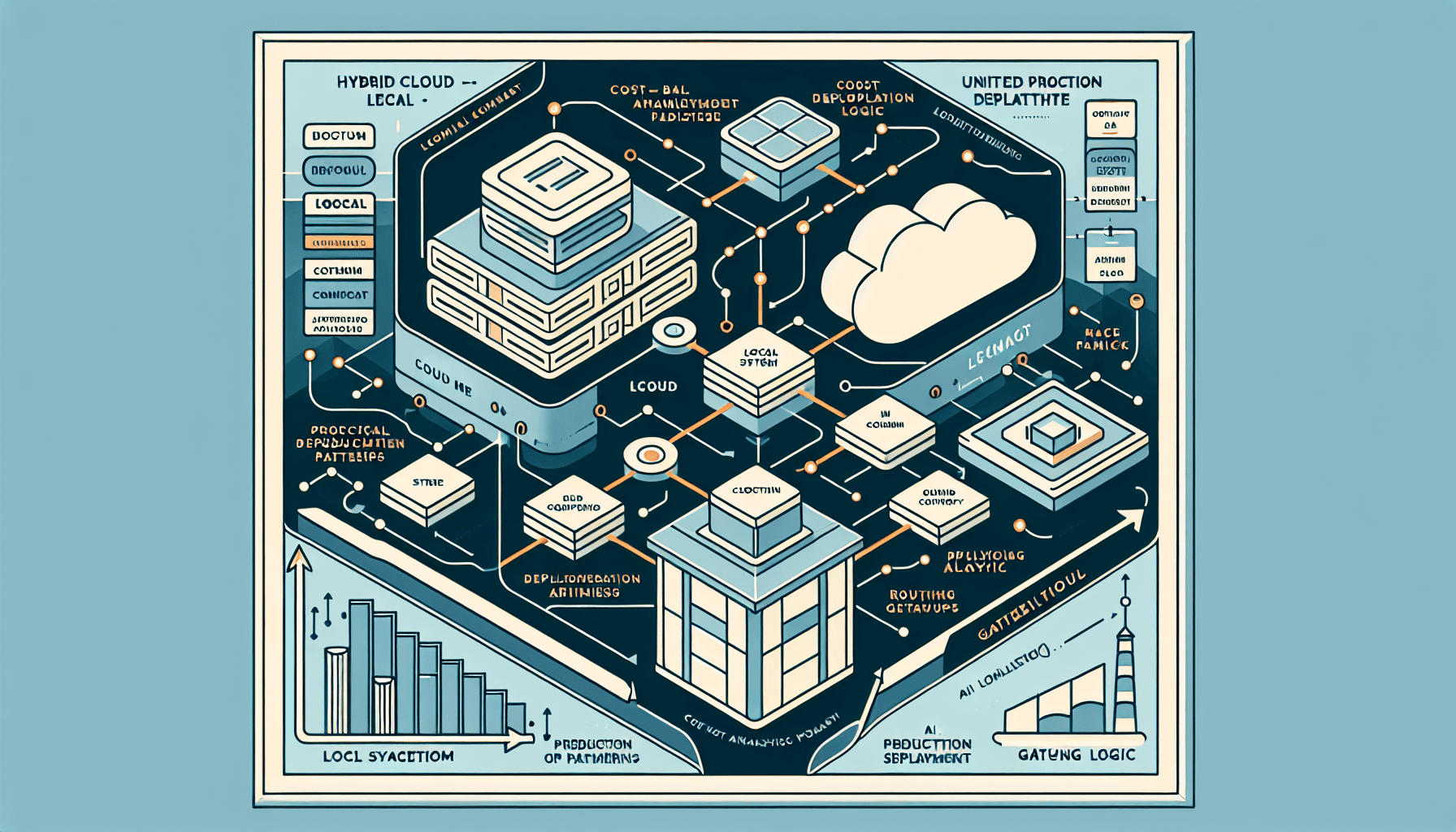
The economics of cloud-only LLM deployments have shifted. This guide walks through the complete implementation of a hybrid cloud-local LLM routing system, covering LiteLLM as the unified gateway, Ollama for local model serving, Anthropic's Claude API as the cloud tier, LangChain for orchestration, and Next.js as the application layer. Table of Contents Why Hybrid LLM Architecture Is Now a Production Necessity Architecture Overview: The Three-Pillar Routing Model Tech Stack and Component Roles Gateway Setup: Configuring LiteLLM with Local and Cloud Providers Implementing the Routing Layer with LangChain Next.js Integration: API Routes and Frontend Streaming Cost-Benefit Analysis: When Hybrid Pays Off Production Deployment Patterns Observability, Logging, and Governance Production Deployment Checklist The Pragmatic Path Forward Why Hybrid LLM Architecture Is Now a Production Necessity How to Build a Hybrid Cloud-Local LLM Routing System Deploy a local model server (Ollama) and pull quantized models matching…