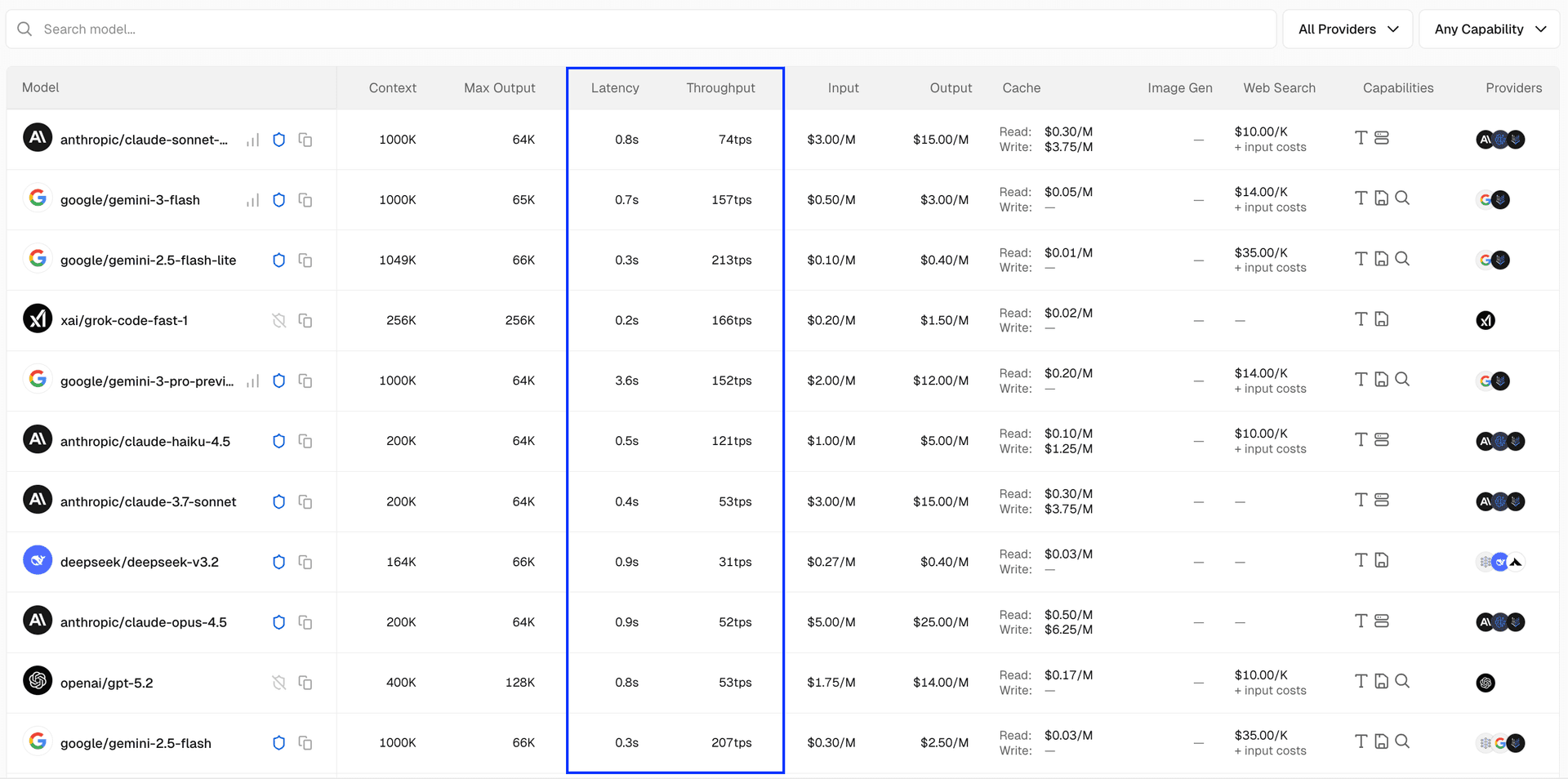
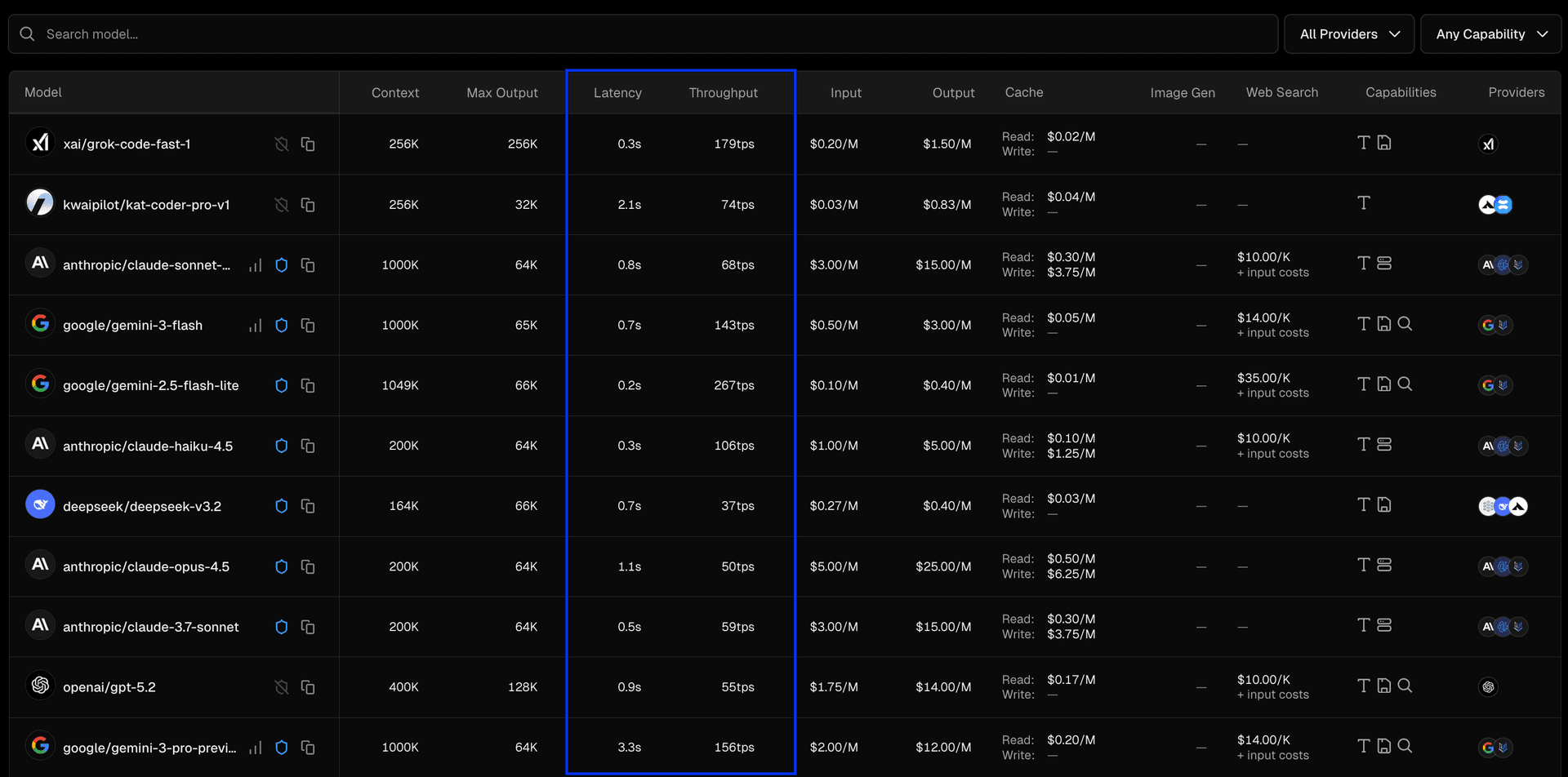
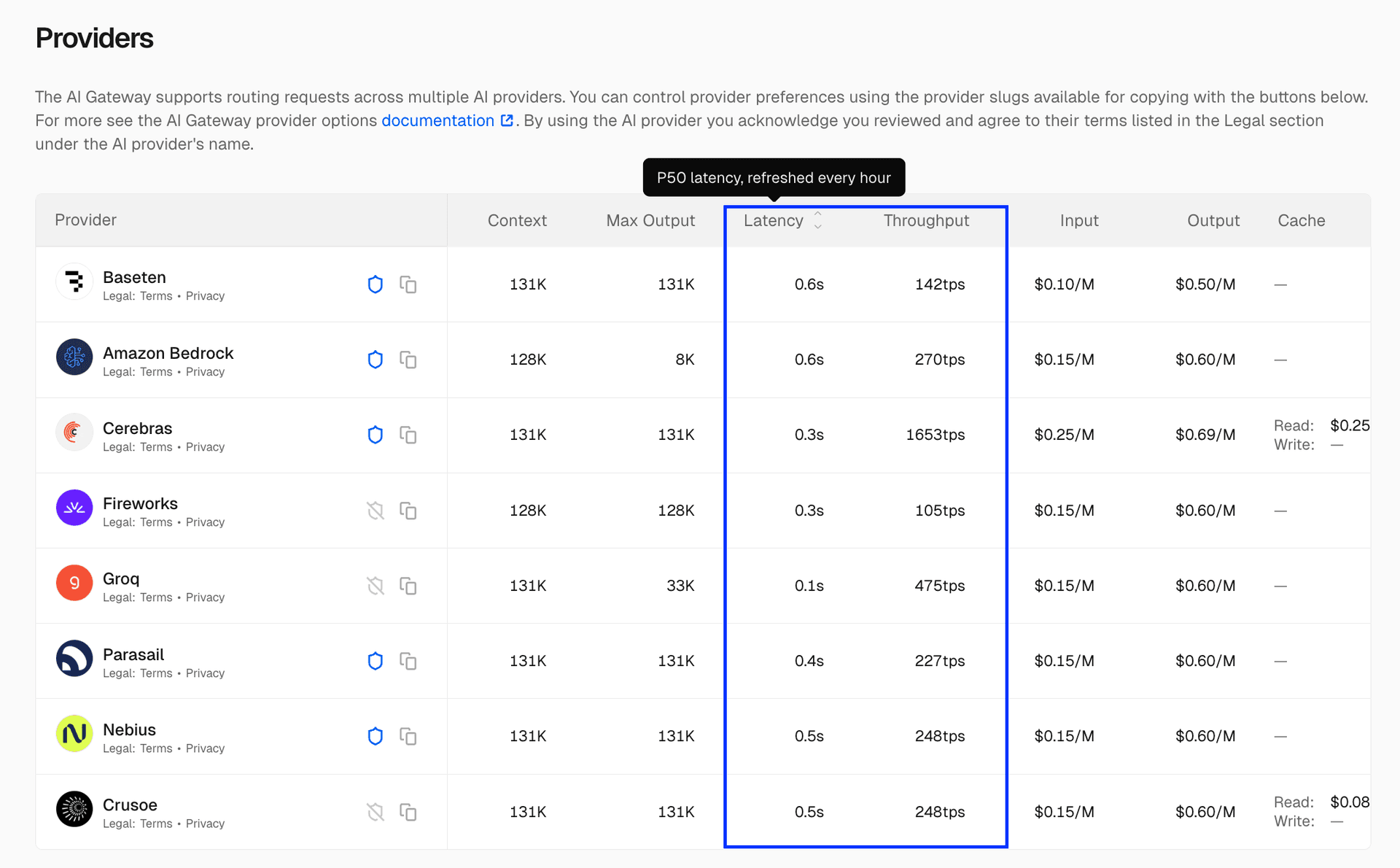
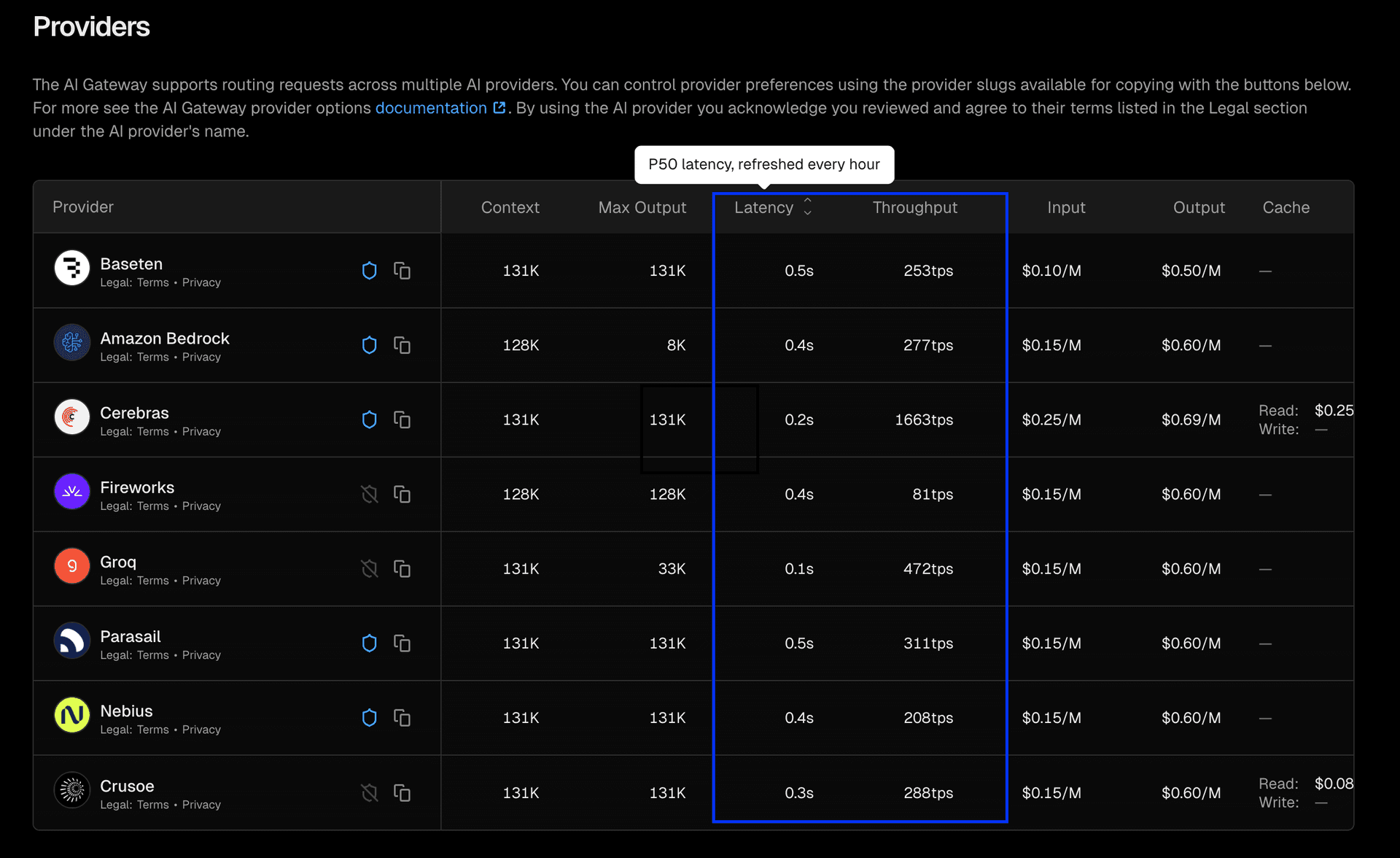
AI Gateway now displays throughput and latency metrics across hundreds of models, helping you choose the right model based on live performance data. Metrics appear in three places and are updated every hour: Model list : Best performance per model (P50 latency and throughput) Model detail pages : Provider-level performance breakdown REST API : Rolling endpoint performance aggregates (latency and throughput, P50/P95) Link to heading Model list The AI Gateway model list now includes sortable columns for latency and throughput. Each row displays the best P50 metrics (lowest latency, highest throughput) for that model across all its available providers. Metrics are updated every hour and based on live AI Gateway customer requests. Sort by throughput to find the fastest token generation, or by latency to find models with the quickest time-to-first-token. Link to heading Model detail pages On the individual model pages, you can see P50 latency and throughput for each provider that has recorded usage.…