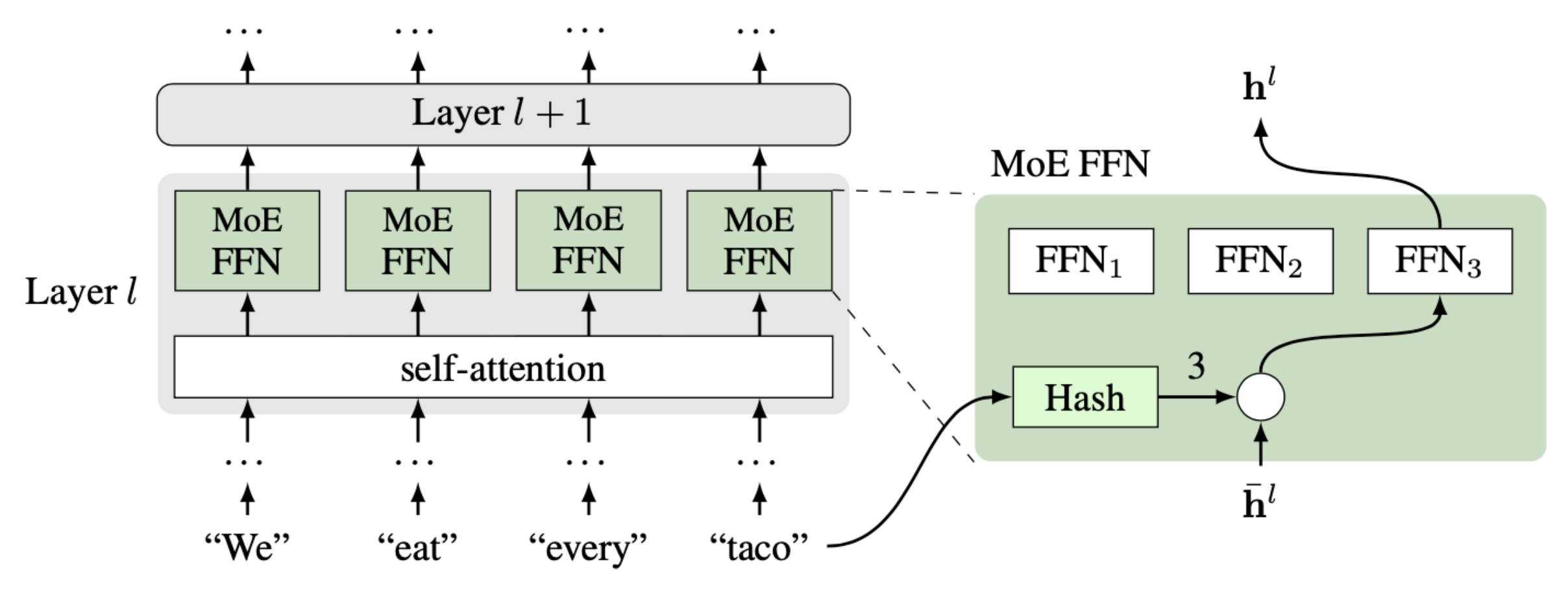
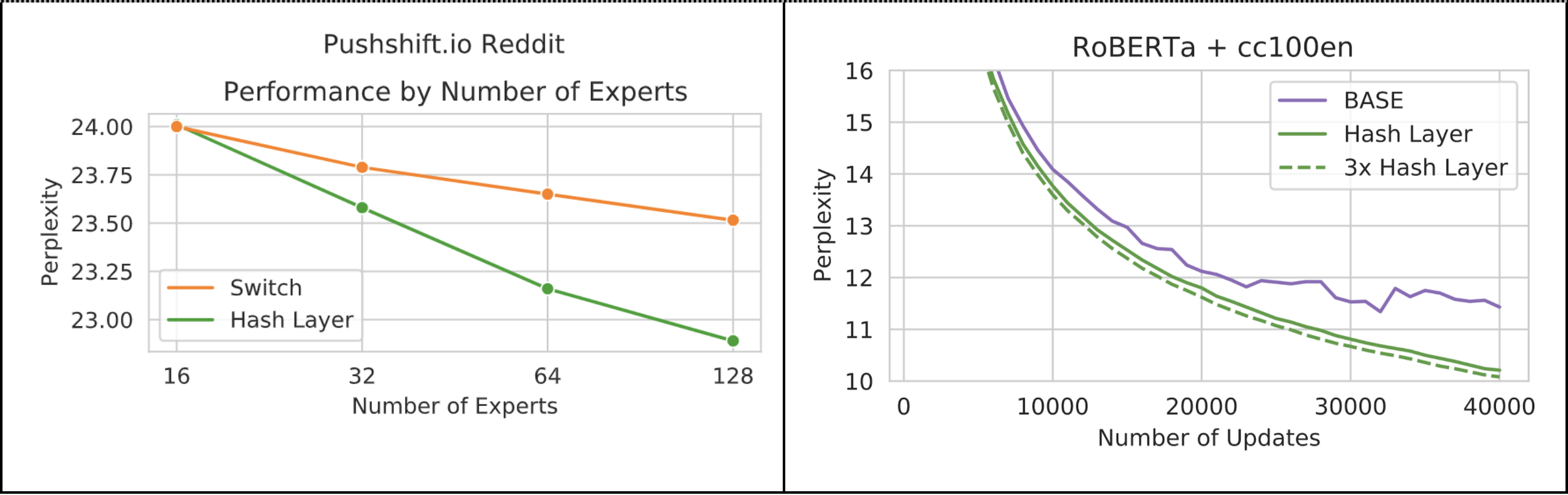
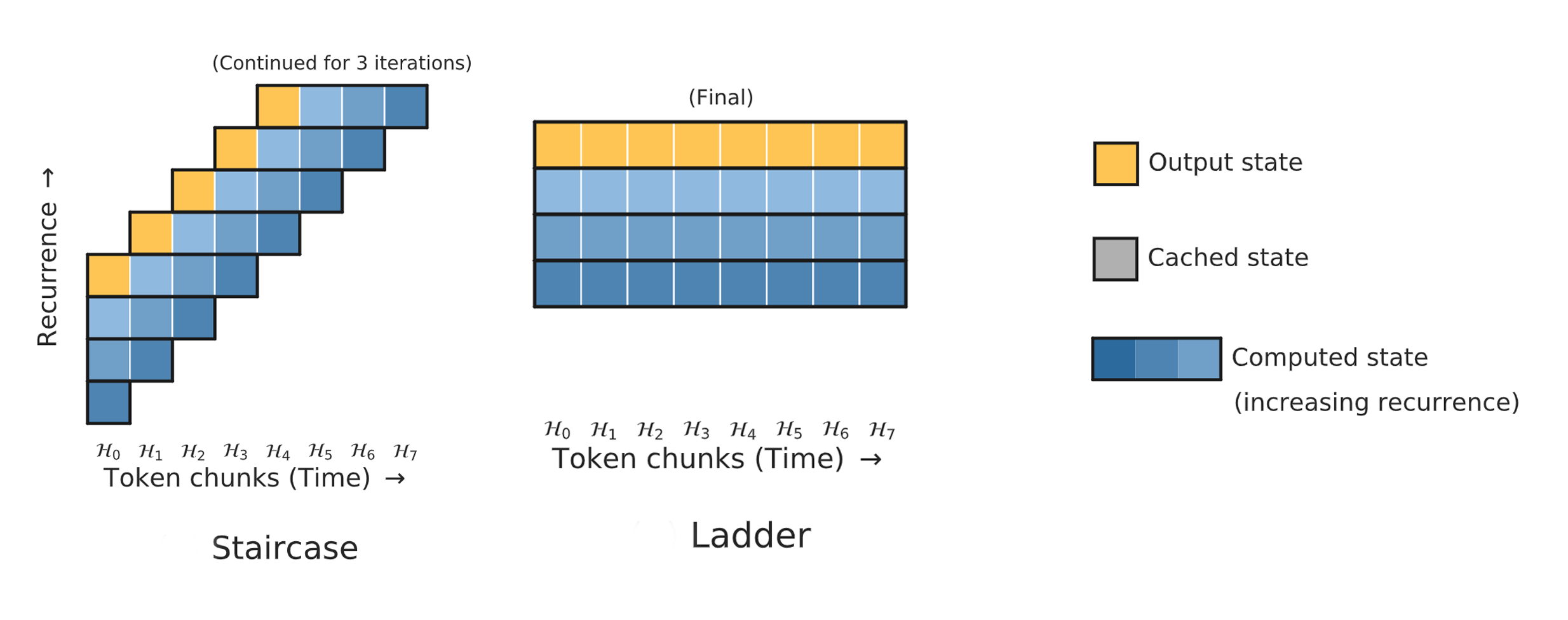
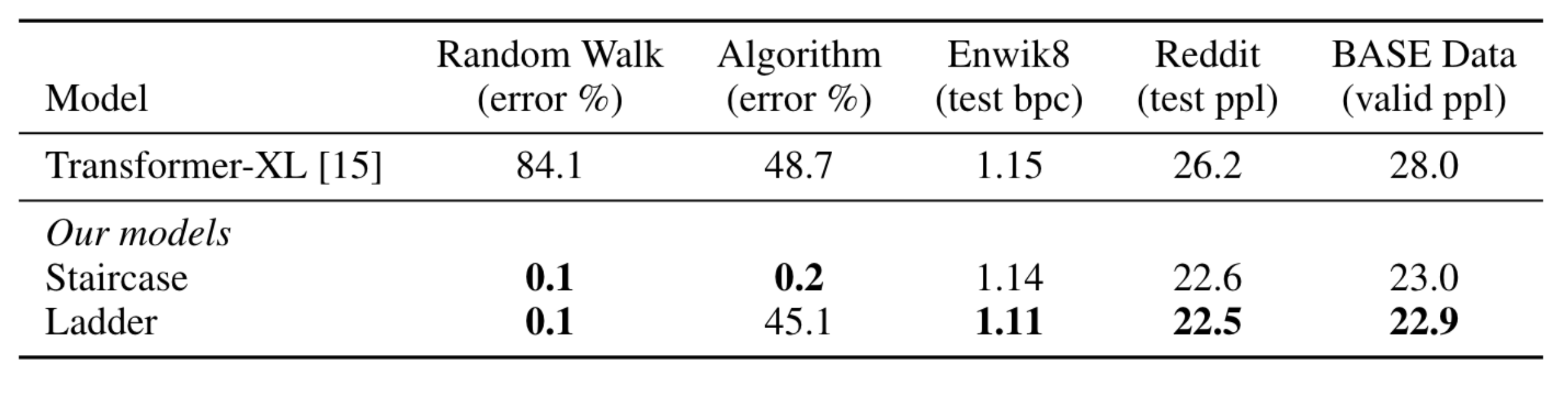
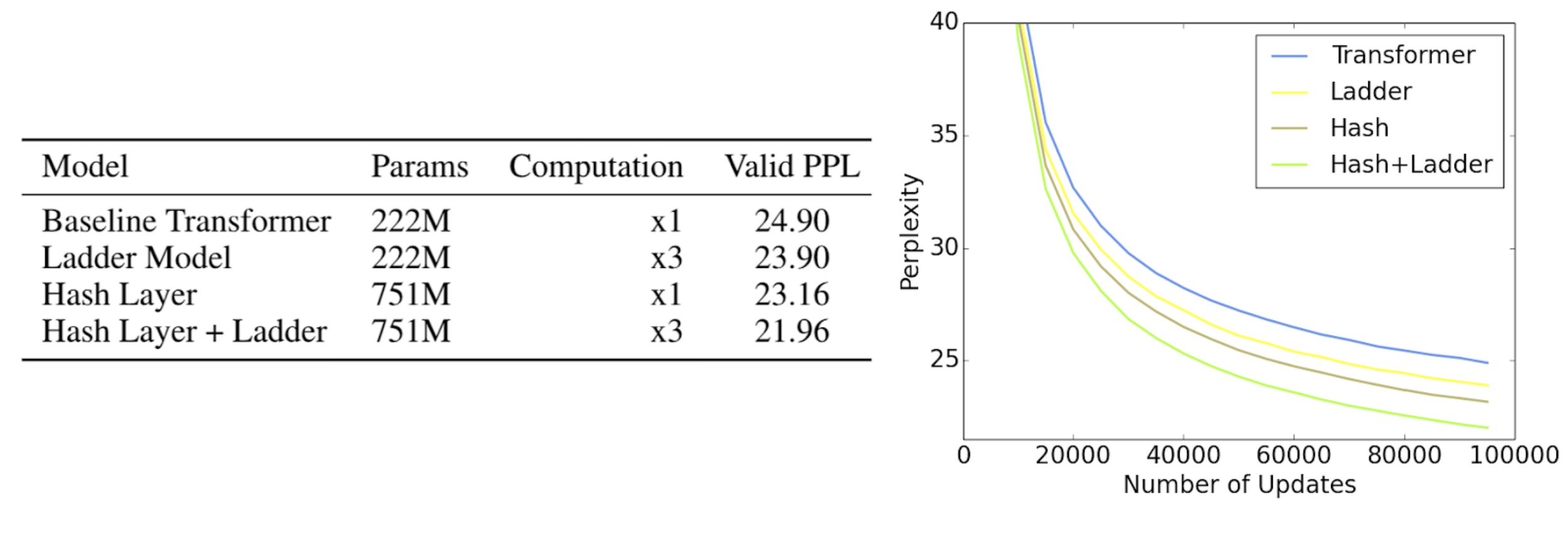
Which one is more important: more parameters or more computation? When we talk about the power of a deep learning model, often the only metric we pay attention to is its size, which is measured by the number parameters in that model. However, the amount of computation to run that model is an important metric too, but it is often overlooked because it is usually tied to the model size. Practitioners can then tend to think of those two metrics as a single thing. This is true most of the time, as each parameter participates in computation only once per input. So if a model has 1 million parameters, then it will take roughly 1 million floating point operations to process an input. This applies to feedforward models, recurrent models, and even Transformers. We are announcing the publication of two new methods that together help study this important question further -- and show that the computation of a model should be considered separately from the model size.…