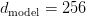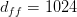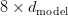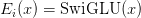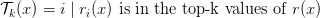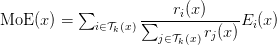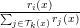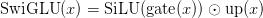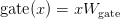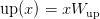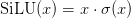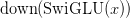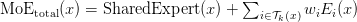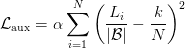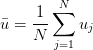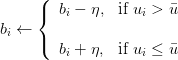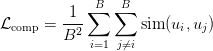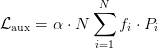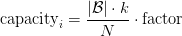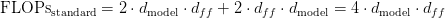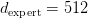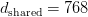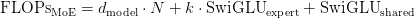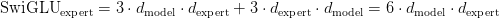Table of Contents DeepSeek-V3 from Scratch: Mixture of Experts (MoE) The Scaling Challenge in Neural Networks Mixture of Experts (MoE): Mathematical Foundation and Routing Mechanism SwiGLU Activation in DeepSeek-V3: Improving MoE Non-Linearity Shared Expert in DeepSeek-V3: Universal Processing in MoE Layers Auxiliary-Loss-Free Load Balancing in DeepSeek-V3 MoE Sequence-Wise Load Balancing for Mixture of Experts Models Expert Specialization in MoE: Emergent Behavior in DeepSeek-V3 Implementation: Building the DeepSeek-V3 MoE Layer from Scratch MoE Design Decisions in DeepSeek-V3: SwiGLU, Shared Experts, and Routing MoE Computational and Memory Analysis in DeepSeek-V3 MoE Expert Specialization in Practice: Real-World Behavior Training Dynamics of MoE: Load Balancing and Expert Utilization Mixture of Experts vs Related Techniques: Switch Transformers and Sparse Models Summary Citation Information In the first two parts of this series, we established the foundations of DeepSeek-V3 by implementing its core…